
将列转到行
将列转到行
提问于 2022-10-12 22:46:54
我有一组数据,在这些数据中,我试图垂直旋转的列存储如下:
testdata <- structure(list(id = c(723L, 621L, NA, NA, NA, NA, NA, NA, NA),
fullName = c("Will Smith", "Chris Rock", "", "", "", "",
"", "", ""), latestPosts.0.locationId = c(212928653L, 34505L,
NA, NA, NA, NA, NA, NA, NA), latestPosts.0.locationName = c("Miami",
"Atlanta", "", "", "", "", "", "", ""), latestPosts.1.locationId = c(1040683L,
20326736L, NA, NA, NA, NA, NA, NA, NA), latestPosts.1.locationName = c("New York",
"London", "", "", "", "", "", "", ""), latestPosts.2.locationId = c(NA,
215307317L, NA, NA, NA, NA, NA, NA, NA), latestPosts.2.locationName = c("",
"Paris", "", "", "", "", "", "", ""), latestPosts.3.locationId = c(1147378L,
34505L, NA, NA, NA, NA, NA, NA, NA), latestPosts.3.locationName = c("Seattle",
"Atlanta", "", "", "", "", "", "", ""), latestPosts.4.locationId = c(1147378L,
NA, NA, NA, NA, NA, NA, NA, NA), latestPosts.4.locationName = c("Seattle",
"", "", "", "", "", "", "", ""), latestPosts.5.locationId = c(238334931,
9432076525, NA, NA, NA, NA, NA, NA, NA), latestPosts.5.locationName = c("San Francisco",
"Brooklyn", "", "", "", "", "", "", ""), latestPosts.6.locationId = c(881699386L,
NA, NA, NA, NA, NA, NA, NA, NA), latestPosts.6.locationName = c("San Diego",
"", "", "", "", "", "", "", ""), latestPosts.7.locationId = c(NA,
234986797L, NA, NA, NA, NA, NA, NA, NA), latestPosts.8.locationId = c(1147378,
9021444765, NA, NA, NA, NA, NA, NA, NA), latestPosts.8.locationName = c("Seattle",
"Cleveland", "", "", "", "", "", "", ""), latestPosts.9.locationId = c(NA,
NA, NA, NA, NA, NA, NA, NA, NA), latestPosts.9.locationName = c(NA,
NA, NA, NA, NA, NA, NA, NA, NA), latestPosts.10.locationId = c(408631288L,
234986797L, NA, NA, NA, NA, NA, NA, NA), latestPosts.10.locationName = c("Portland",
"Orlando", "", "", "", "", "", "", ""), latestPosts.11.locationId = c(52043757619,
34505, NA, NA, NA, NA, NA, NA, NA), latestPosts.11.locationName = c("Nashville",
"Atlanta", "", "", "", "", "", "", "")), class = "data.frame", row.names = c(NA,
-9L))我试图将latestPosts.n.locationId或latestPosts.n.locationName (在本例中,n是两个数字之间的占位符)不为空或不为NA时作为支点,使最终输出看起来是这样的:
testdata_exp <- structure(list(id = c(723L, 724L, 725L, 726L, 727L, 728L, 729L,
730L, 731L, 621L, 622L, 623L, 624L, 625L, 626L, 627L, 628L, 629L
), fullName = c("Will Smith", "Will Smith", "Will Smith", "Will Smith",
"Will Smith", "Will Smith", "Will Smith", "Will Smith", "Will Smith",
"Chris Rock", "Chris Rock", "Chris Rock", "Chris Rock", "Chris Rock",
"Chris Rock", "Chris Rock", "Chris Rock", "Chris Rock"), locationId = c(212928653,
1040683, 1147378, 1147378, 238334931, 881699386, 1147378, 408631288,
52043757619, 34505, 20326736, 215307317, 34505, 9432076525, 234986797,
9021444765, 234986797, 34505), locationName = c("Miami Beach, Florida",
"Starbucks", "University of Evansville", "University of Evansville",
"Downtown Evansville", "Garden Of The Gods", "University of Evansville",
"Phi Gamma Delta - Epsilon Iota", "Nashville Pride", "University of the South",
"Riverview Camp For Girls", "Chattanooga, Tennessee", "University of the South",
"Grand Sirenis Riviera Maya Resort", "", "Sleepyhead Coffee",
"Sewanee, Tennessee", "University of the South")), class = "data.frame", row.names = c(NA,
-18L))或用于视觉表现:
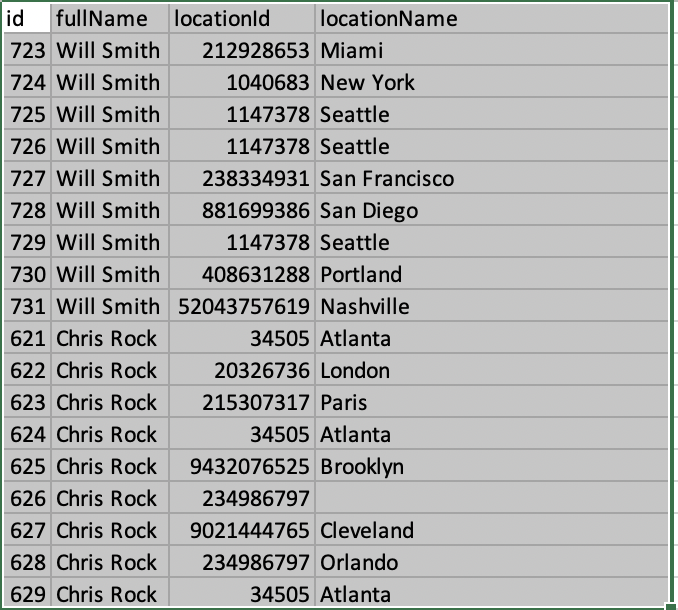
有几件事要记住:
- 从dataset到dataset,
latestPosts.n.locationId或latestPosts.n.locationName的数量可能会发生变化,因此最好考虑不知道会有多少数据集。这个例子上升到11,但其他时候可能或多或少。
- 如果有
locationId存在,并不总是意味着会有一个匹配的locationName字段。使用此数据作为示例,有一个latestPosts.7.locationId字段,但没有后续的latestPosts.7.locationName字段.
回答 2
Stack Overflow用户
发布于 2022-10-12 23:28:57
下面是另一个变体(也使用pivot_longer)
library(dplyr)
library(tidyr)
testdata %>%
pivot_longer(-c(id, fullName),
names_to = c("n", ".value"),
names_pattern = "latestPosts\\.([0-9]+)\\.(.+)") %>%
select(-n) %>%
filter(!((is.na(locationId) | locationId == '') & (is.na(locationName) | locationName == '')))
#> # A tibble: 18 × 4
#> id fullName locationId locationName
#> <int> <chr> <dbl> <chr>
#> 1 723 Will Smith 212928653 Miami
#> 2 723 Will Smith 1040683 New York
#> 3 723 Will Smith 1147378 Seattle
#> 4 723 Will Smith 1147378 Seattle
#> 5 723 Will Smith 238334931 San Francisco
#> 6 723 Will Smith 881699386 San Diego
#> 7 723 Will Smith 1147378 Seattle
#> 8 723 Will Smith 408631288 Portland
#> 9 723 Will Smith 52043757619 Nashville
#> 10 621 Chris Rock 34505 Atlanta
#> 11 621 Chris Rock 20326736 London
#> 12 621 Chris Rock 215307317 Paris
#> 13 621 Chris Rock 34505 Atlanta
#> 14 621 Chris Rock 9432076525 Brooklyn
#> 15 621 Chris Rock 234986797 <NA>
#> 16 621 Chris Rock 9021444765 Cleveland
#> 17 621 Chris Rock 234986797 Orlando
#> 18 621 Chris Rock 34505 AtlantaStack Overflow用户
发布于 2022-10-12 23:15:55
你可以
library(tidyverse)
testdata %>%
rename_all(~sub("latestPosts\\.", "", .x)) %>%
mutate(across(contains("location"), as.character)) %>%
mutate(rownum = row_number()) %>%
pivot_longer(contains("location")) %>%
separate(name, into = c("group", "var")) %>%
group_by(id, fullName, group, rownum) %>%
summarise(var = c("locationId", "locationName"),
value = if(n() == 1) c(value, NA) else value, .groups = "drop") %>%
pivot_wider(names_from = var, values_from = value) %>%
select(id, fullName, locationId, locationName) %>%
filter((!is.na(locationName) & nzchar(locationName)) | !is.na(locationId)) %>%
mutate(locationId = as.numeric(locationId))
#> # A tibble: 18 x 4
#> id fullName locationId locationName
#> <int> <chr> <dbl> <chr>
#> 1 621 Chris Rock 34505 Atlanta
#> 2 621 Chris Rock 20326736 London
#> 3 621 Chris Rock 234986797 Orlando
#> 4 621 Chris Rock 34505 Atlanta
#> 5 621 Chris Rock 215307317 Paris
#> 6 621 Chris Rock 34505 Atlanta
#> 7 621 Chris Rock 9432076525 Brooklyn
#> 8 621 Chris Rock 234986797 NA
#> 9 621 Chris Rock 9021444765 Cleveland
#> 10 723 Will Smith 212928653 Miami
#> 11 723 Will Smith 1040683 New York
#> 12 723 Will Smith 408631288 Portland
#> 13 723 Will Smith 52043757619 Nashville
#> 14 723 Will Smith 1147378 Seattle
#> 15 723 Will Smith 1147378 Seattle
#> 16 723 Will Smith 238334931 San Francisco
#> 17 723 Will Smith 881699386 San Diego
#> 18 723 Will Smith 1147378 Seattle 页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/74048720
复制相关文章
相似问题
腾讯云开发者
