
在使用pyarrow write_dataset时可以指定压缩吗?
在使用pyarrow write_dataset时可以指定压缩吗?
提问于 2022-10-30 20:25:41
我希望能够控制分区时使用的压缩类型(默认是snappy)。
import numpy.random
import pyarrow as pa
import pyarrow.dataset as ds
data = pa.table(
{
"day": numpy.random.randint(1, 31, size=100),
"month": numpy.random.randint(1, 12, size=100),
"year": [2000 + x // 10 for x in range(100)],
}
)
ds.write_dataset(
data,
"./tmp/partitioned",
format="parquet",
existing_data_behavior="delete_matching",
partitioning=ds.partitioning(
pa.schema(
[
("year", pa.int16()),
]
),
),
)我不清楚,从医生那里,这是否真的有可能
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-10-31 04:27:59
file_options
pyarrow.dataset.FileWriteOptions,可选 FileFormat特定的写选项,使用FileFormat.make_write_options()函数创建。
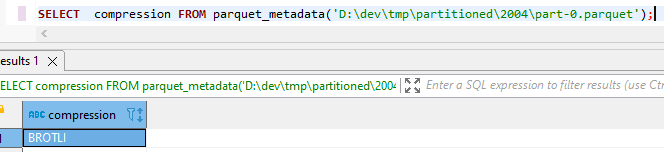
您可以使用docs中提到的任何压缩选项- snappy、gzip、brotli、zstd、lz4、none。
下面的代码使用brotli压缩编写数据集。
import numpy.random
import pyarrow as pa
import pyarrow.dataset as ds
data = pa.table(
{
"day": numpy.random.randint(1, 31, size=100),
"month": numpy.random.randint(1, 12, size=100),
"year": [2000 + x // 10 for x in range(100)],
}
)
file_options = ds.ParquetFileFormat().make_write_options(compression='brotli')
ds.write_dataset(
data,
"./tmp/partitioned",
format="parquet",
existing_data_behavior="delete_matching",
file_options=file_options,
partitioning=ds.partitioning(
pa.schema(
[
("year", pa.int16()),
]
),
),
)
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/74256499
复制相关文章
相似问题
腾讯云开发者
