
Google对ARRAY_ROW的问题进行排序,通过兰博达。额外的空行会导致公式出错。
最近,我找到了如何通过Passing QUERY() as a parameter to a Google Sheets LAMBDA function将更复杂的参数准确地传递到LAMBDA中。我想把这些知识应用到数据集中的其他地方。我找到了一个很好的候选人,我想通过编程的方式根据键列对范围进行排序。
问题是,所有内容都是通过编程方式通过公式(黄色单元格F2:H2)生成/检索的。这很容易用菜单排序方法来完成,但是为了通过编程实现这一点,我相信我需要使用LAMBDA (通过,因为我在lambda中不做任何修改就可以传递参数)。
问题是,只有在我的工作表中没有任何其他行时,这才有效。如果我再加一行,就会出错。
工作守则
每个项目都按预期正确排序和显示。根据日期进行反向排序,然后根据键进行反向排序。您可以注意到,总共有52行,我的工作表中没有空行。
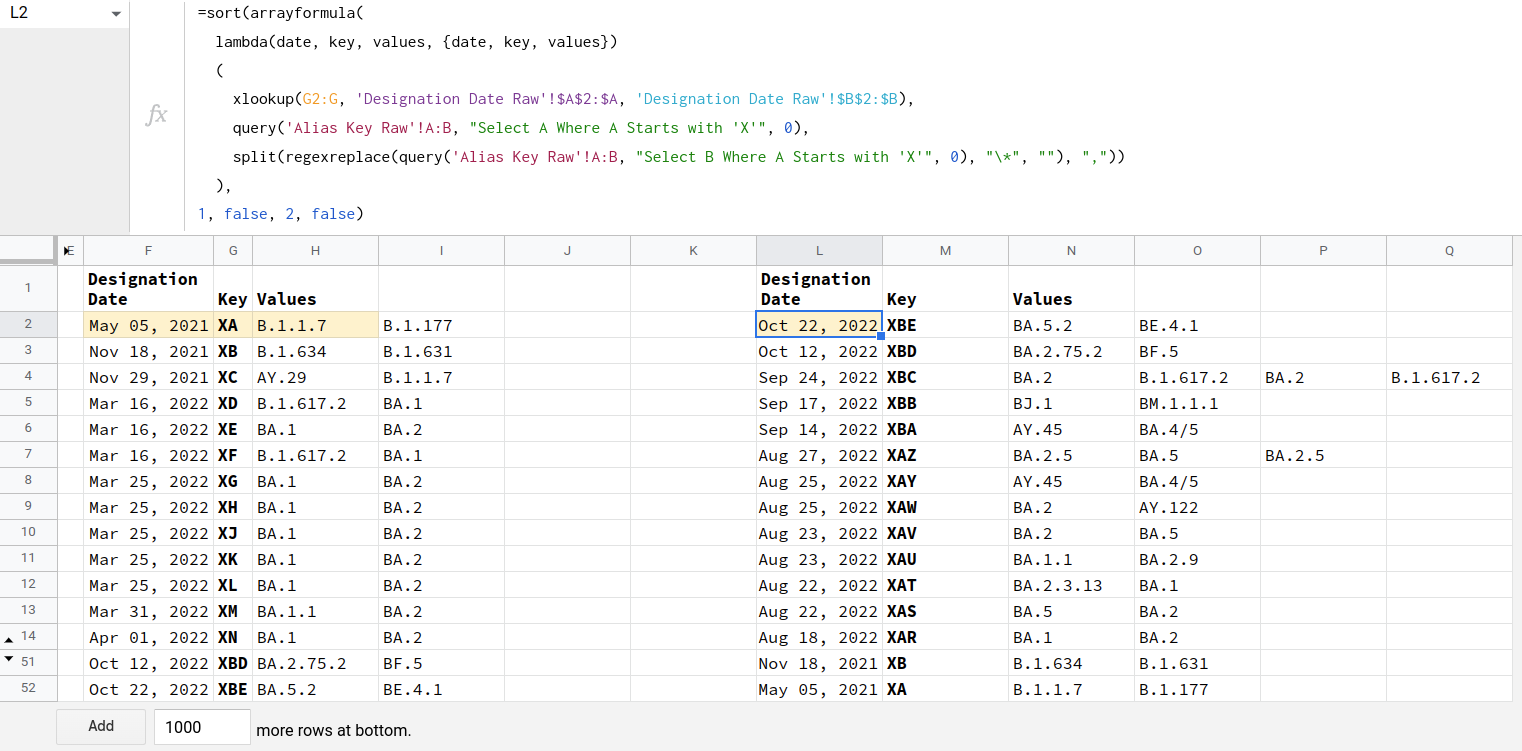
在L2 I中,有以下代码..。
=sort(arrayformula(
lambda(date, key, values, {date, key, values})
(
xlookup(G2:G, 'Designation Date Raw'!$A$2:$A, 'Designation Date Raw'!$B$2:$B),
query('Alias Key Raw'!A:B, "Select A Where A Starts with 'X'", 0),
split(regexreplace(query('Alias Key Raw'!A:B, "Select B Where A Starts with 'X'", 0), "\*", ""), ","))
),
1, false, 2, false)// F2
=iferror(arrayformula(xlookup(G2:G, 'Designation Date Raw'!$A$2:$A, 'Designation Date Raw'!$B$2:$B)))// G2
=query('Alias Key Raw'!A:B, "Select A Where A Starts with 'X'", 0)// H2
=arrayformula(split(regexreplace(query('Alias Key Raw'!A:B, "Select B Where A Starts with 'X'", 0), "\*", ""), ","))增加一条线
除第53号线外,无变动
Error
Function ARRAY_ROW parameter 2 has mismatched row size. Expected: 52. Actual: 51.
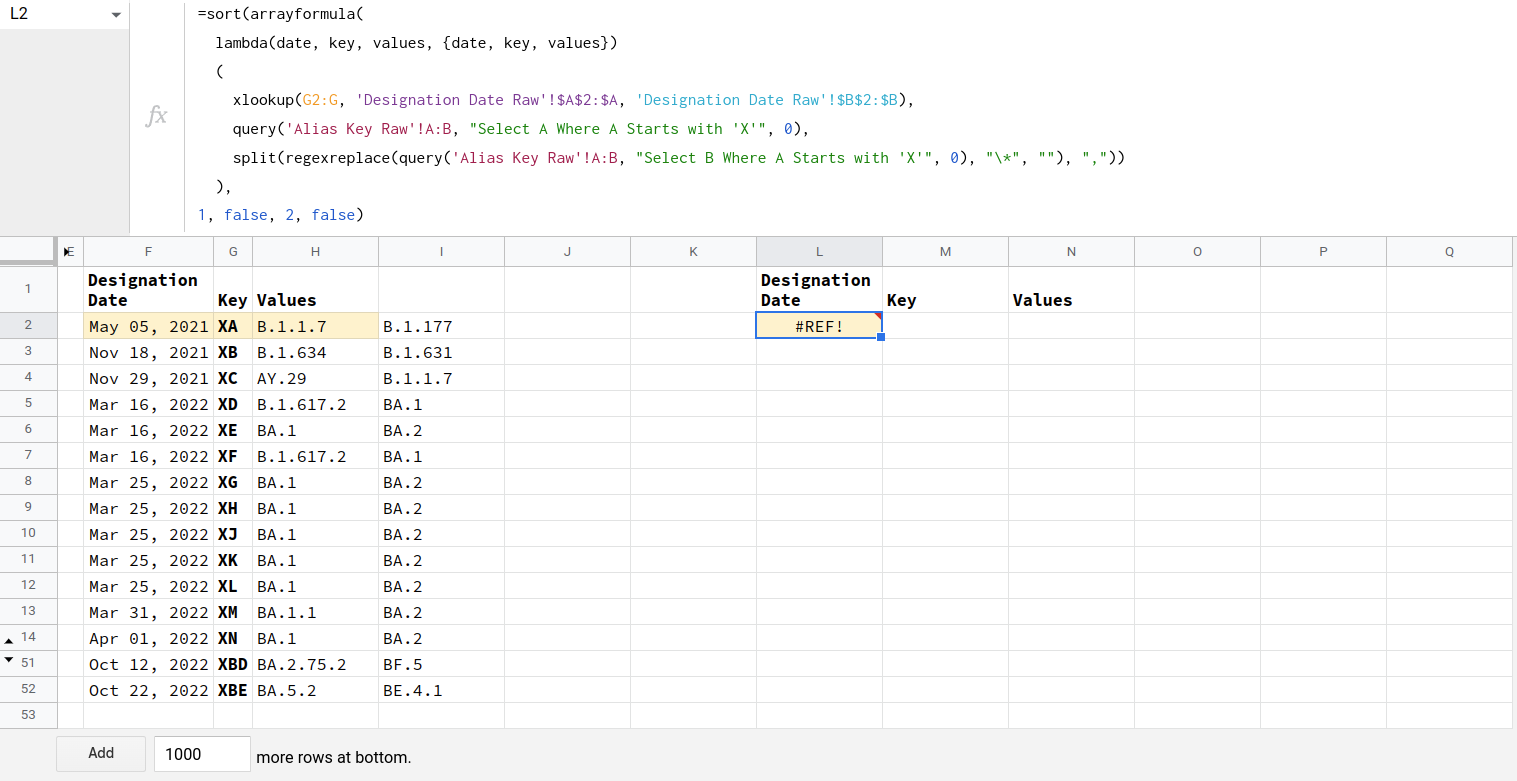
更多信息
我的意图是将F2:H2中的3个公式替换为L2中的单个公式。此外,所有代码都按预期工作,但我不希望截断我的工作表以删除所有空行。
存在问题差
这个问题与我的代码工作时的Error: Function ARRAY_ROW parameter 2 has mismatched row size. Expected: 1. Actual: 10434不同,它的错误是由于公式的外部因素,例如添加新的工作表行。这也使用了新的LAMBDA函数,它的操作方式不同。
Stack Overflow用户
发布于 2022-11-26 17:33:28
我会得到ARRAY_ROW错误,仅仅是因为每个输入列的行不匹配。尽管非空行的数量相同,但我使用G2:G作为一列数据,使用query(...)处理其他列是错误的根源。G2:G列有其他空行的数据下落不明。
只要将G2:G替换为等效的query(...)函数,无论向工作表中添加了多少额外的空行,错误都会消失。

=SORT(arrayformula(
lambda(date, key, values, {date, key, values})
(
xlookup(query('Raw AK'!A:B, "Select A Where A Starts with 'X'", 0), 'Designation Date Raw'!$A$2:$A, 'Designation Date Raw'!$B$2:$B),
query('Raw AK'!A:B, "Select A Where A Starts with 'X'", 0),
split(regexreplace(query('Raw AK'!A:B, "Select B Where A Starts with 'X'", 0), "\*", ""), ","))
),
1, false, 2, false)注意:当工作表中没有额外的空白行时,
G2:G工作的原因仅仅是因为两个不同的数据集(G2:G和query(...)有相同的行数)。
避免ARRAY_ROW错误的Lambda
可以扩展lambda的使用,以确保ARRAY_ROW错误更难以生成。当数据有一对一的关系时,这是可行的。
对于lambda,您必须传递要在lambda函数中使用的值。通过在另一个lambda的参数列表中使用lambda,可以强制使用所有计算中可以使用的单个数据集。
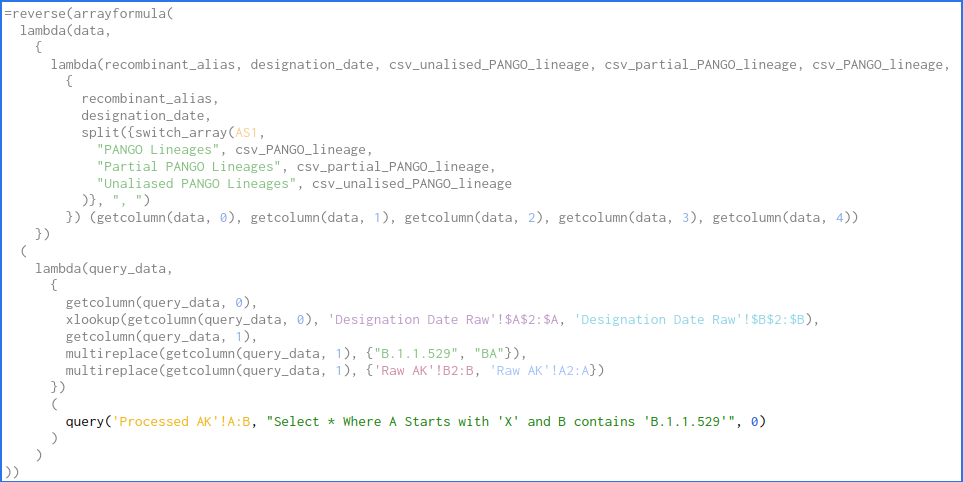
如您所见,我现在只有一个query(...)函数。所有底层数据都基于这一个函数调用。我可以将这些数据与其他工作表中的其他数据进行变异,但它仍然是基于query(...)调用的。
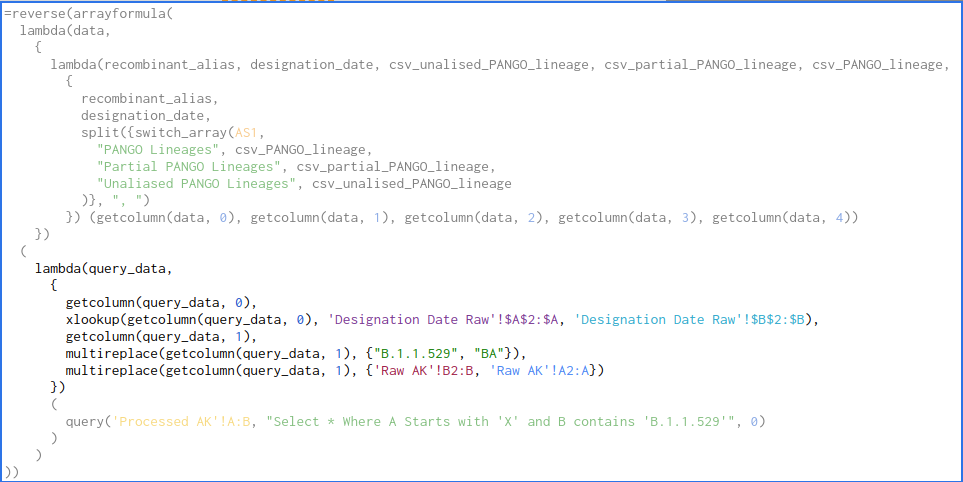
我获取query_data并将其划分为每个单独的列,并对这些列执行额外的计算。注意,我可以添加更多
=reverse(arrayformula(
lambda(data,
{
lambda(recombinant_alias, designation_date, csv_unalised_PANGO_lineage, csv_partial_PANGO_lineage, csv_PANGO_lineage,
{
recombinant_alias,
designation_date,
split({switch_array(AS1,
"PANGO Lineages", csv_PANGO_lineage,
"Partial PANGO Lineages", csv_partial_PANGO_lineage,
"Unaliased PANGO Lineages", csv_unalised_PANGO_lineage
)}, ", ")
}) (getcolumn(data, 0), getcolumn(data, 1), getcolumn(data, 2), getcolumn(data, 3), getcolumn(data, 4))
})
(
lambda(query_data,
{
getcolumn(query_data, 0),
xlookup(getcolumn(query_data, 0), 'Designation Date Raw'!$A$2:$A, 'Designation Date Raw'!$B$2:$B),
getcolumn(query_data, 1),
multireplace(getcolumn(query_data, 1), {"B.1.1.529", "BA"}),
multireplace(getcolumn(query_data, 1), {'Raw AK'!B2:B, 'Raw AK'!A2:A})
})
(
query('Processed AK'!A:B, "Select * Where A Starts with 'X' and B contains 'B.1.1.529'", 0)
)
)
))
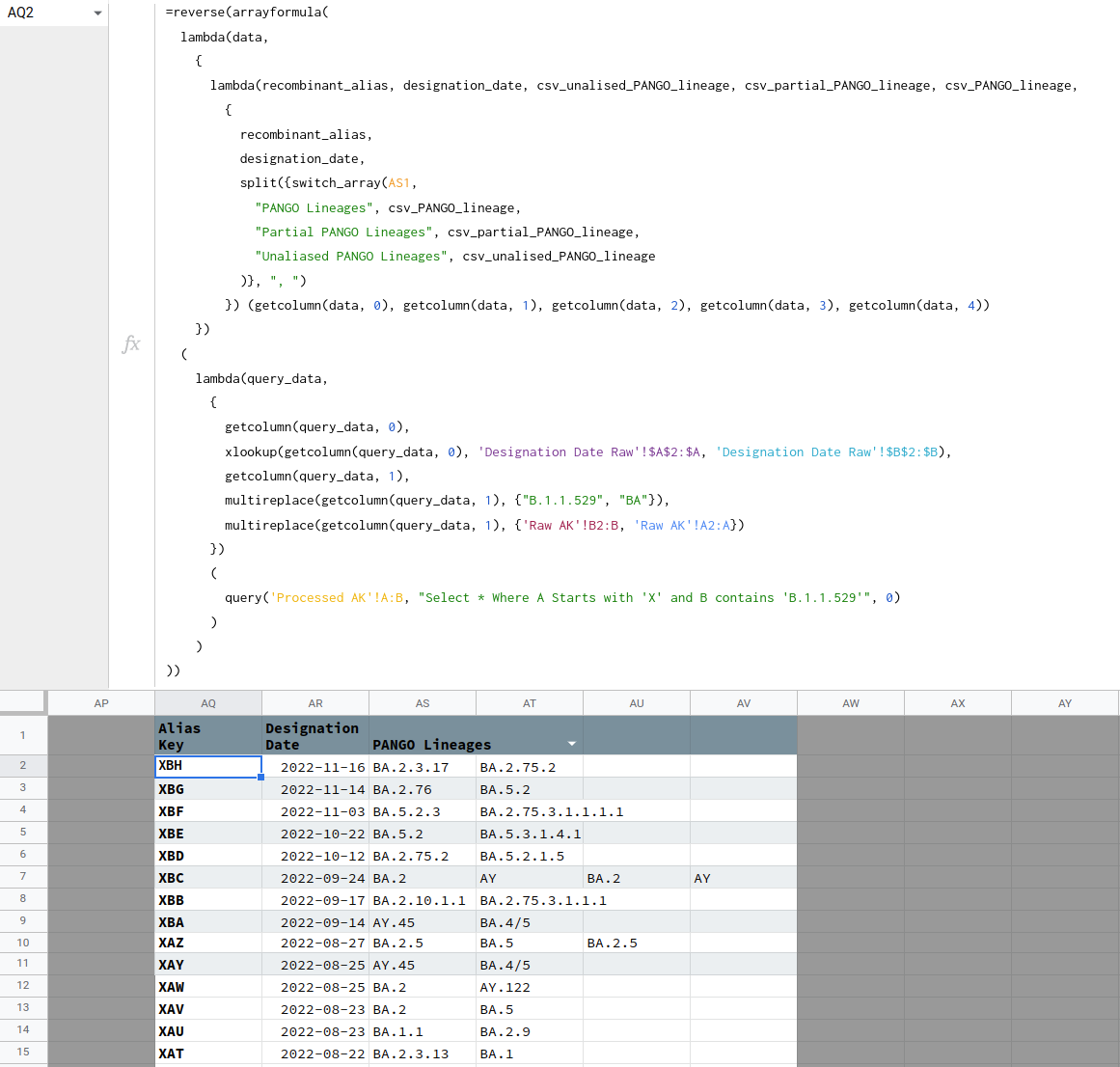
这是一些证明,这个公式是有效的,如预期。
注释:我使用Google创建自定义函数
getcolumn(...)、switch_array(...)和multireplace(...)
switch_array(...)正在模拟内置的switch(...)函数,但是可以在数组上工作。
getcolumn(...)将从数组中检索特定列的数据。
multireplace(...)是一个非正则表达式的多个文本替换函数,可用于数据数组.。
https://stackoverflow.com/questions/74277783
复制相似问题
腾讯云开发者
