
使用image_to_data()时,pytesseract不保留前导零
使用image_to_data()时,pytesseract不保留前导零
提问于 2022-11-02 15:08:57
我使用pytesseract处理以下图像:
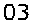
当我使用image_to_string()函数
config = "--oem 3 -l eng --psm 7"
pytesseract.image_to_string(potential_image, config = config)我得到了正确的"03“输出。但是,当我使用image_to_data()函数时
predict = pytesseract.image_to_data(potential_image, config = config, output_type="data.frame")
print(predict)
predict = predict[predict["conf"] != -1]
try:
detected = " ".join([str(int(a)) if isinstance(a, float) else str(a) for a in predict["text"].tolist()])
confidence = predict["conf"].iloc[0]
print("Converted detected:", detected)
print("with confidence:", confidence)
except:
pass我得到:
level page_num block_num par_num line_num word_num left top width height conf text
4 5 1 1 1 1 1 4 4 25 16 95.180374 3.0
Converted detected: 3
with confidence: 95.180374其中,前导0未被保留,其结果是一个浮点数,稍后我必须将其转换为int / string。是否有方法保留文本输出,使其与image_to_string()相同?
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-11-30 18:23:04
与其使用data.frame作为输出类型,不如使用常规Python字典:
pytesseract.image_to_data(image, config = config, output_type = pytesseract.Output.DICT)页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/74291461
复制相关文章
相似问题
腾讯云开发者
