
将两个.csv文件合并为一个,只保留一个头- in bash。
将两个.csv文件合并为一个,只保留一个头- in bash。
提问于 2022-11-08 13:55:40
我在同一个目录中有两个.csv文件,列数相同,我想将它们合并成一个文件,但只保留第一个文件的一个头。文件名总是不同的,只有前缀保持不变:
orderline_123456.csv
Order_number,Quantity,Price
100,10,25.3
101,15,30.2orderline_896524.csv
Order_number,Quantity,Price
102,20,12.33
103,3,3.4输出文件应该类似于:
file_load.csv
Order_number,Quantity,Price
100,10,25.3
101,15,30.2
102,20,12.33
103,3,3.4这已经在shell脚本文件中了,因为从现在开始,我只需要接受一个文件,但是现在我必须合并两个文件:
awk '(NR-1)%2{$1=$1}1' RS=\" ORS=\" orderline_*.csv >> file_to_load.csv我试着把它改成
awk 'FNR == 1 && NR != 1 {next} (NR-1)%2{$1=$1}1' RS=\" ORS=\" orderline_*.csv >> file_to_load.csv但是我在输出中得到了两次头。
你能帮帮我吗?这个命令到底应该是什么样子?我需要保留它之前的定义。
谢谢!
回答 3
Stack Overflow用户
发布于 2022-11-08 14:05:57
你在找
awk 'NR == 1 || FNR > 1' file ...NR是所有记录的计数,以及
FNR是当前文件的记录号。
Stack Overflow用户
发布于 2022-11-08 14:55:07
有时解决方案是用简单的步骤来划分任务。
1.获取第一行,即头,并将其存储为变量。
https://stackoverflow.com/a/2439587/3957754
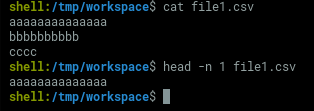
header=$(head -n 1 file1.csv)2.获取文件的所有行,但第一行除外。
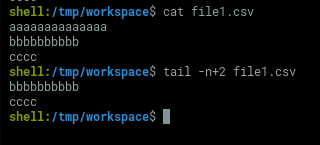
body=$(tail -n+2 file1.csv)对两个文件重复此操作
3.标题和n个机构
csv_merger.sh
header=$(head -n 1 file1.csv)
body1=$(tail -n+2 file1.csv)
body2=$(tail -n+2 file2.csv)
echo "$header" > merged.csv
echo "$body1" >> merged.csv
echo "$body2" >> merged.csv结果

您可以扩展此脚本以处理更多文件。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/74361927
复制相关文章
相似问题
腾讯云开发者
