
使用累积和将总额分配给一列,但以另一列的限额为限
使用累积和将总额分配给一列,但以另一列的限额为限
提问于 2022-11-08 14:37:35
背景:我有一份数百个部门的清单,我想将预算分配如下:
- 每个部门在给定的月数内都有一个AMT_TOTAL预算。他们也有一个不能超过的每月LIMIT_MONTH限额。
- 每个部门都计划尽快花掉他们的预算,我们假设他们会一直花到每月的限额,直到AMT_TOTAL用完为止。考虑到这一假设,预计他们将花费的金额为AMT_ALLOC_MONTH
。

我的目标是计算AMT_ALLOC_MONTH列,给定LIMIT_MONTH和AMT_TOTAL列。根据我所阅读和搜索的内容,我相信填充和累计()的组合可以完成这项工作。到目前为止,我所生成的Python数据文件如下所示:
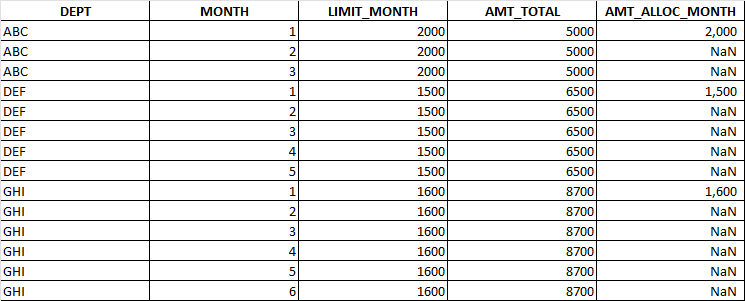
我计划使用以下行填充NaN:
table['AMT_ALLOC_MONTH'] = min((table['AMT_TOTAL'] - table.groupby('DEPT')['AMT_ALLOC_MONTH'].cumsum()).ffill, table['LIMIT_MONTH'])我的目标是让AMT_TOTAL减去按DEPT分组的AMT_ALLOC_MONTH的累积和(不包括NaN值);然后将结果与列LIMIT_MONTH中的值进行比较,并在NaN单元格中填充较小的值。这个过程是重复的,直到每个部门的所有NaN单元都被填满。
不用说,结果并没有像我预期的那样出现;代码行只在单元格之后的第一个NaN中使用值;随后的NaN单元只是复制它上面的值。如果有解决问题的方法,或者是一种新的、更直观的方法来解决这个问题,请提供帮助。真的很感激!
回答 1
Stack Overflow用户
发布于 2022-11-08 15:34:28
试试这个:
for department in table['DEPT'].unique():
subset = table[table['DEPT'] == department]
for index, row in subset.iterrows():
subset = table[table['DEPT'] == department]
cumsum = subset.loc[:index-1, 'AMT_ALLOC_MONTH'].sum()
limit = row['LIMIT_MONTH']
remaining = row['AMT_TOTAL'] - cumsum
table.at[index, 'AMT_ALLOC_MONTH'] = min(remaining, limit)我想它不太雅致,但它似乎很管用。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/74362512
复制相关文章
相似问题
腾讯云开发者
