
基于单个代码的上游河段识别
基于单个代码的上游河段识别
提问于 2022-11-10 15:10:03
我使用的是来自HydroSHEDS的全球河网划分。在这个数据集中,每条河流都有单独的8位代码(HYRIV_ID)。dataset包含一些额外的字段,但是对于这个任务,我将只依赖NEXT_DOWN,它为我们提供了下一个下游河流的代码。
要重新创建下图中的数据集,我有
a <- c(41397427, 41397438, 41397439, 41397440, 41397466, 41397467, 41397494, 41397495, 41397512, 41397513, 41397514, 41397566, 41397584)
b <- c(41397438, 41397494, 41397466, 41397439, 41397438, 41397440, 41397401, 41397440, 41397466, 41397439, 41397495, 41397495, 41397494)
# Data frame of individual codes for reach id (HYRIV_ID) and the next downstream reach (NEXT_DOWN)
df <- data.frame(HYRIV_ID = a, NEXT_DOWN = b)
# Point A and B HYRIV_ID
id <- c(41397494, 41397495)

现在,我需要使用向量HYRIV_ID中的id识别A和B点的所有上游河流。因为真正的数据有更多的点,所以我创建了一个循环来遍历存储在id中的所有代码。
贝娄你能找到我的企图
# NOTE: Although the loop will run, the output of i = 1 (point A) is not correct, as it's only identifying the first upstream reaches
pt_up <- list() # create a list to store the upstream HYRIV_ID for each target code in id
for (i in 1:length(id)){
n <- id[[i]] # creates vector with target HYRIV_ID, where all upstream reaches will also be stored
tmp_id <- df[df$NEXT_DOWN == id[[i]],]$HYRIV_ID # identifies reaches which have n as NEXT_DOWN reach
# if the target reach is the most upstream, then it can't be downstream of any other
if(length(tmp_id) == 0){
n <- n
# if not, I need to find the next upstream reaches
}else{
# If tmp_id is higher than 1 I need to find the upstream reaches of each HYRIV_ID in tmp_id
# I use a second loop go through codes stored in tmp_id
for (j in 1:length(tmp_id)){
tmp_id2 <- df[df$NEXT_DOWN == tmp_id[[j]],]$HYRIV_ID
if(length(tmp_id2) == 0){
n <- append(n, tmp_id[[j]]) # if tmp_id2 as no upstream reaches, then I add the codes in tmp_id to n, as this will be the only upstream reaches
}else{
n <- append(n, tmp_id2)
}
}
}
pt_up[[i]] <- n # add reaches HYRIV_ID upstream of target reach to the list
names(pt_up)[i] <- id[[i]] # name list element to keep track of target reach
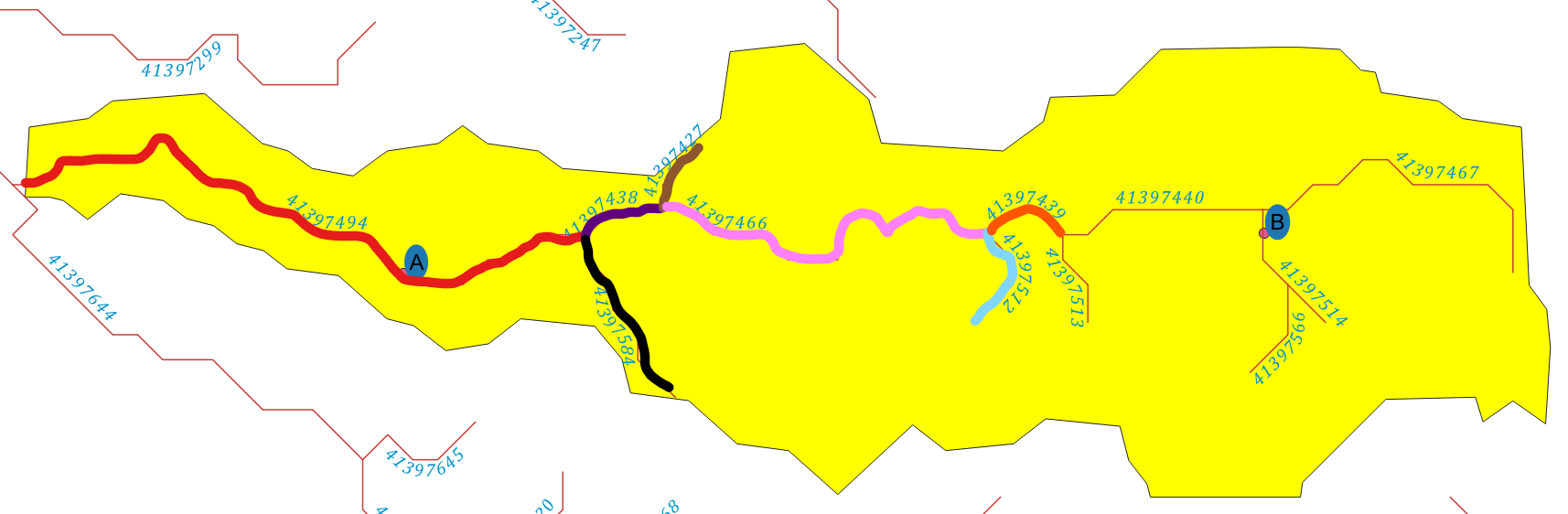
}这对于B点(i = 2)来说很好,在这两个上游到达代表端点(图中的红色和紫色)。
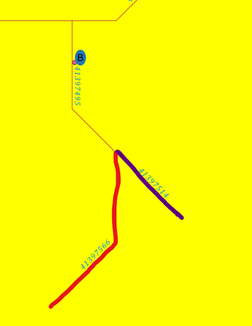
但是,对于A点,我有多个分支(下一个图中的有色示例并不是详尽无遗的),我需要在第二个循环中对每个新的范围重复这个过程。我认为这可能是通过在repeat函数中放置第二个循环来实现的,但我不知道如何实现。
编辑
最后我得到了一个使用重复循环的解决方案,但是我确信有一个更干净的方法来完成这个任务!
pt_up <- list() # create a list to store the upstream HYRIV_ID for each target code in id
for (i in 1:length(id)){
n <- id[[i]] # creates vector with target HYRIV_ID, where all upstream reaches will also be stored
tmp_id <- df[df$NEXT_DOWN == id[[i]],]$HYRIV_ID # identifies reaches which have n as NEXT_DOWN reach
# if the target reach is the most upstream, then it can't be downstream of any other
if(length(tmp_id) == 0){
n <- n
# if not, I need to find the next upstream reaches
}else{
# If tmp_id is higher than 1 I need to find the upstream reaches of each HYRIV_ID in tmp_id
# I use a second loop go through codes stored in tmp_id
n <- append(n, tmp_id) # adds the HYRIV_ID of the first upstream reaches
tmp_id2 <- tmp_id # create a new vector that will be updated within the loop, without overwriting
####### NEW SECTION ADDED HERE ######
repeat{ # this is where I added the repeat loop
for (j in 1:length(tmp_id2)){ # loops through all HYRIV_IDs stored in tmp_2 and repeats after tmp_id2 is updated
if(length(df[df$NEXT_DOWN == tmp_id2[[j]],]$HYRIV_ID) == 0){
n <- n # if tmp_id2 has no upstream reaches, then I add the codes in tmp_id to n, as this will be the only upstream reaches
}else{
id2 <- df[df$NEXT_DOWN == tmp_id2[[j]],]$HYRIV_ID # HYRIV_ID upstream of codes stored in tmp_id2
n <- append(n, id2) # add codes to n
}
}
tmp_id2 <- id2 # updated tmp_id2 with the new IDs so to repeat the loop
if (length(df[df$NEXT_DOWN %in% tmp_id2,]$HYRIV_ID) == 0 & unique(tmp_id2 %in% n) == TRUE){
break
} # this will stop the repeat loop when there are no upstream reaches left
}
####### END OF NEW SECTION ######
pt_up[[i]] <- n # add reaches HYRIV_ID upstream of target reach to the list
names(pt_up)[i] <- id[[i]] # name list element to keep track of target reach
}
}回答 1
Stack Overflow用户
回答已采纳
发布于 2022-11-12 16:48:52
您的上游和下游河流段的数据模型是一个有向无圈图,该图的节点(顶点)表示河流段,节点之间的边缘(连接)表示上游->下游关系。
您可以使用R包igraph来表示数据并在其上进行计算。给定有向无圈图,如何确定给定节点的所有祖先?
library(igraph)
a <- c(41397427, 41397438, 41397439, 41397440, 41397466, 41397467, 41397494, 41397495, 41397512, 41397513, 41397514, 41397566, 41397584)
b <- c(41397438, 41397494, 41397466, 41397439, 41397438, 41397440, 41397401, 41397440, 41397466, 41397439, 41397495, 41397495, 41397494)
df <- data.frame(HYRIV_ID = a, NEXT_DOWN = b)
xx <- graph_from_data_frame(df)现在,使用subcomponent函数查找从指定顶点可以到达的所有节点,这些节点“进入”该节点(即祖先链):
# Point A
subcomponent(xx, "41397494", "in")
## + 13/14 vertices, named, from a2cc5ff:
## [1] 41397494 41397438 41397584 41397427 41397466 41397439 41397512 41397440
## [9] 41397513 41397467 41397495 41397514 41397566
# Point B
subcomponent(xx, "41397495", "in")
# + 3/14 vertices, named, from a2cc5ff:
# [1] 41397495 41397514 41397566如果需要,现在可以很容易地排除感兴趣的节点。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/74391197
复制相关文章
相似问题
腾讯云开发者
