
pySpark替换行子集上的空值
pySpark替换行子集上的空值
提问于 2022-11-16 06:26:39
我有一个pySpark dataframe,其中有我想要替换的空值,但是要替换的值对于不同的组是不同的。
我的数据看起来是这样的(appologies,我没有办法通过它作为文本):
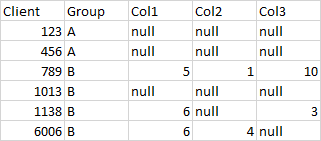
对于组A,我希望用-999替换空值;对于组B,我想用0替换空值。
目前,我将数据分成几个部分,然后执行一个df = df.fillna(-999)。
有更有效的方法吗?在psudo代码中,我是沿着df = df.where(col('group') == A).fillna(lit(-999)).where(col('group') == B).fillna(lit(0))的路线思考的,但当然,这是行不通的。
回答 2
Stack Overflow用户
发布于 2022-11-16 07:19:17
您可以使用when
from pyspark.sql import functions as F
# Loop over all the columns you want to fill
for col in ('Col1', 'Col2', 'Col3'):
# compute here conditions to fill using a value or another
fill_a = F.col(col).isNull() & (F.col('Group') == 'A')
fill_b = F.col(col).isNull() & (F.col('Group') == 'B')
# Fill the column based on the different conditions
# using nested `when` - `otherwise`.
#
# Do not forget to add the last `otherwise` with the original
# values if none of the previous conditions have been met
filled_col = (
F.when(fill_a, -999)
.otherwise(
F.when(fill_b, 0)
.otherwise(F.col(col))
)
)
# 'overwrite' the original column with the filled column
df = df.withColumn(col, filled_col)Stack Overflow用户
发布于 2022-11-16 16:01:41
另一种可能的选择是对每一列使用coalesce,其中包含替换值的“填充”列:
import pyspark.sql.functions as F
for c in ['Col1', 'Col2', 'Col3']:
df = df.withColumn(c, F.coalesce(c, F.when(F.col('group') == 'A', -999)
.when(F.col('group') == 'B', 0)))页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/74456021
复制相关文章
相似问题
腾讯云开发者
