
使用熊猫在另一个数据中从数据中搜索值
使用熊猫在另一个数据中从数据中搜索值
提问于 2022-11-24 17:36:36
我有两个数据集,病人数据和疾病数据。患者数据集有以字母数字编码格式编写的疾病,我希望在疾病数据集中搜索这些疾病,以显示疾病名称。
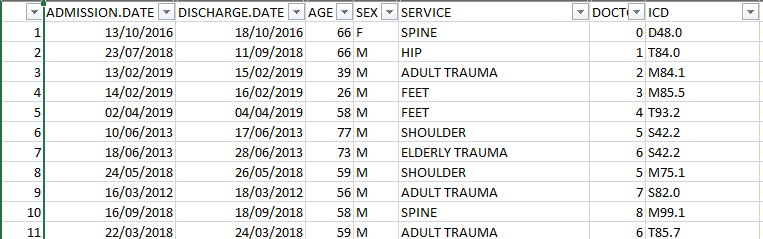
病人数据集快照
疾病数据集快照
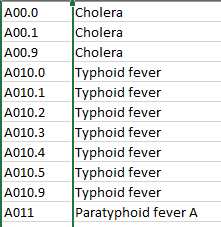
我希望在ICD列上使用groupby函数,找出疾病的发生情况,并将其按降序排列,以显示前5位。我一直试图找到相同的引用,但无法。
会很感激你的帮助!
编辑!!
avg2 = joined.groupby('disease_name').TIME_DELTA.mean().disease_name.value_counts()我得到了一个错误"'Series‘对象没有属性'disease_name'“
回答 1
Stack Overflow用户
发布于 2022-11-24 18:05:06
假设您拥有的数据位于两只熊猫的数据中,名为patients和diseases,并且疾病数据集的列名为disease_id和disease_name,这可能是一个解决方案:
joined = patients.merge(diseases, left_on='ICD', right_on='disease_id')
top_5 = joined.disease_name.value_counts().head(5)此解决方案将数据连接在一起,然后使用value_counts而不是分组。它应该解决我认为是你所要求的,即使它不是你所要求的功能。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/74564513
复制相关文章
相似问题
腾讯云开发者
