
熊猫JSON规范化-选择正确的记录路径
熊猫JSON规范化-选择正确的记录路径
提问于 2021-11-30 14:16:22
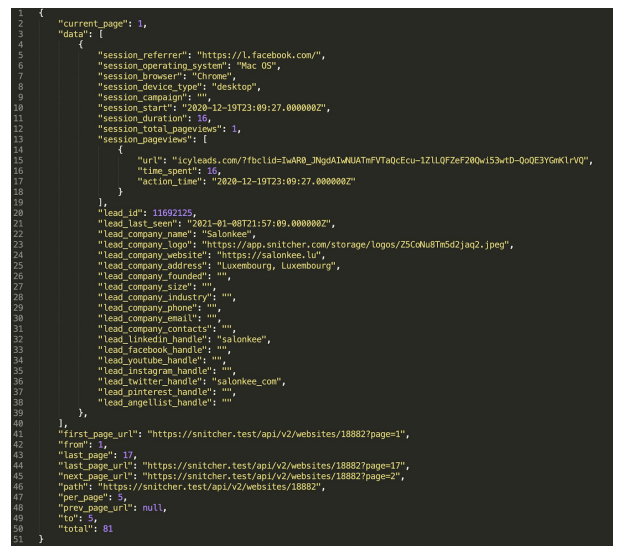
我试图弄清楚如何规范下面采样的嵌套JSON响应。
现在,json_normalize(res,record_path=['data'])提供了我所需要的大部分数据,但我真正想要的是"session_pageviews“列表/dict中包含数据列表/dic属性的细节。
我尝试了json_normalize(res,record_path=['data', ['session_pageviews']], meta = ['data']),但是我得到了一个错误:ValueError: operands could not be broadcast together with shape (32400,) (180,)
我也尝试过json_normalize(res,record_path=['data'], max_level = 1),但这并没有取消session_pageviews
任何帮助都将不胜感激!
回答 1
Stack Overflow用户
回答已采纳
发布于 2021-11-30 14:41:51
您可以尝试将以下函数应用于您的json:
def flatten_nested_json_df(df):
df = df.reset_index()
s = (df.applymap(type) == list).all()
list_columns = s[s].index.tolist()
s = (df.applymap(type) == dict).all()
dict_columns = s[s].index.tolist()
while len(list_columns) > 0 or len(dict_columns) > 0:
new_columns = []
for col in dict_columns:
horiz_exploded = pd.json_normalize(df[col]).add_prefix(f'{col}.')
horiz_exploded.index = df.index
df = pd.concat([df, horiz_exploded], axis=1).drop(columns=[col])
new_columns.extend(horiz_exploded.columns) # inplace
for col in list_columns:
#print(f"exploding: {col}")
df = df.drop(columns=[col]).join(df[col].explode().to_frame())
new_columns.append(col)
s = (df[new_columns].applymap(type) == list).all()
list_columns = s[s].index.tolist()
s = (df[new_columns].applymap(type) == dict).all()
dict_columns = s[s].index.tolist()
return df通过这样做:
df1= flatten_nested_json_df(df)哪里
df = pd.json_normalize(json)这应该会给你包含在你的json中的所有信息。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/70170844
复制相关文章
相似问题
腾讯云开发者
