
读取具有可变列数的CSV文件
读取具有可变列数的CSV文件
提问于 2021-11-26 18:42:19
我有一个CSV文件,看起来
K1
,Value
M1,0
M2,10
M3,3
K2
,Value,Value,Value
M1,4,6,3
M2,7,3,4
M3,10,2,6
K1
,Value,Value
M1,0,4
M2,10,2
M3,3,7
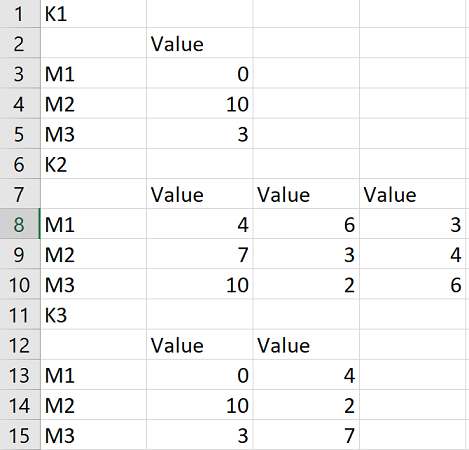
该文件按5行分组。例如,第一个组的名称是K1,后面是一个具有固定3行和1列的dataframe。组中的行数是固定的,但列数是可变的。K1有1列,K2有3列,K3有2列。我想阅读它来形成一个字典,其中键是组的名称、K1、K2或K3,值是与组名相关联的dataframe。
简单的类似于read_csv的df = pd.read_csv('test.batch.csv')失败了,出现了以下错误
Traceback (most recent call last):
File "test.py", line 8, in <module>
df = pd.read_csv('test.batch.csv')
File "/home/mahmood/.local/lib/python3.8/site-packages/pandas/io/parsers.py", line 610, in read_csv
return _read(filepath_or_buffer, kwds)
File "/home/mahmood/.local/lib/python3.8/site-packages/pandas/io/parsers.py", line 468, in _read
return parser.read(nrows)
File "/home/mahmood/.local/lib/python3.8/site-packages/pandas/io/parsers.py", line 1057, in read
index, columns, col_dict = self._engine.read(nrows)
File "/home/mahmood/.local/lib/python3.8/site-packages/pandas/io/parsers.py", line 2061, in read
data = self._reader.read(nrows)
File "pandas/_libs/parsers.pyx", line 756, in pandas._libs.parsers.TextReader.read
File "pandas/_libs/parsers.pyx", line 771, in pandas._libs.parsers.TextReader._read_low_memory
File "pandas/_libs/parsers.pyx", line 827, in pandas._libs.parsers.TextReader._read_rows
File "pandas/_libs/parsers.pyx", line 814, in pandas._libs.parsers.TextReader._tokenize_rows
File "pandas/_libs/parsers.pyx", line 1951, in pandas._libs.parsers.raise_parser_error
pandas.errors.ParserError: Error tokenizing data. C error: Expected 2 fields in line 7, saw 4我知道read_csv()文件没有正确格式化,所以我想知道是否还有其他类似的读取函数可以使用。有什么想法吗?
回答 2
Stack Overflow用户
回答已采纳
发布于 2021-11-26 19:57:04
我的想法是从一个空白的中间字典开始。
然后从输入文件(键)中读取一行,并将以下4行作为值,并将它们添加到字典中。
最后一步是“映射”此词典,使用字典理解,将每个(字符串)值更改为DataFrame。
为此,您可以使用read_csv,将当前键的值作为源内容传递。
因此,源代码可以是:
wrk = {}
with open('Input.csv') as fp:
while True:
cnt1 += 1
line = fp.readline()
if not line:
break
key = line.strip()
txt = [ fp.readline().strip() for i in range(4) ]
txt = '\n'.join(txt)
wrk[key] = txt
result = { k: pd.read_csv(io.StringIO(v), index_col=[0]) for k, v in wrk.items() }但请注意,read_csv的工作方式产生了副作用:
如果列名不是唯一的,那么Pandas会在这些“重复”列中添加一个点和连续数字。
因此,例如,K2密钥的内容是:
Value Value.1 Value.2
M1 4 6 3
M2 7 3 4
M3 10 2 6或者每个输入“部分”中的实际列名并不相同?
总之,至少这段代码允许您在读取单个DataFrame时绕过有关相同列数的限制。
Stack Overflow用户
发布于 2021-11-29 03:09:32
下面是我的实现,如我在注释中提到的那样,使用csv.reader,并解析产生的列表列表。您会注意到,我不得不暂时命名索引列,以便将其设置为dataframe的索引。
import csv
import pandas as pd
import numpy as np
INPUT_FILE = r"multidf.csv"
my_df_source = {}
rowcount = 0 # no data parsed
# read file into dictionary entries (key: (headers, datarows))
for row in csv.reader(open(INPUT_FILE,"r")):
if len(row) == 1: # single entry lists are df keys
if rowcount: # store in-process df, if any
my_df_source[df_key] = df_headers, df_rows
df_key = row[0]
rowcount = 0
else:
if rowcount: # rows after row 0 are data
df_rows.append(row)
else: # row 0 is headers
row[0]='index' # create temporary index label
df_headers = row
df_rows = []
rowcount += 1
if rowcount: # store last df
my_df_source[df_key] = df_headers, df_rows
# create dataframes
my_dfs = {}
for key,(headers,data) in my_df_source.items():
my_dfs[key] = pd.DataFrame(np.array(data),columns=headers).set_index('index')
my_dfs[key].index.name=None # remove temporary label
for key, df in my_dfs.items():
print(key)
print(df)页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/70128797
复制相关文章
相似问题
腾讯云开发者
