
Python + BeautifulSoup:如何从href属性获得完整链接?
Python + BeautifulSoup:如何从href属性获得完整链接?
提问于 2021-11-14 06:47:00
我正在整理一个网络爬虫进行实践和学习,并发现了一些问题。我最初的思维过程是..。
在给定页面上查找
- ,查找所有href属性。如果href值是有效链接,则转到这个新链接,如果href值是一条路径(例如“/
/病人-门户”或“/services/财务-帮助”),则继续使用href,则将其追加到当前URL的末尾,并再次继续。
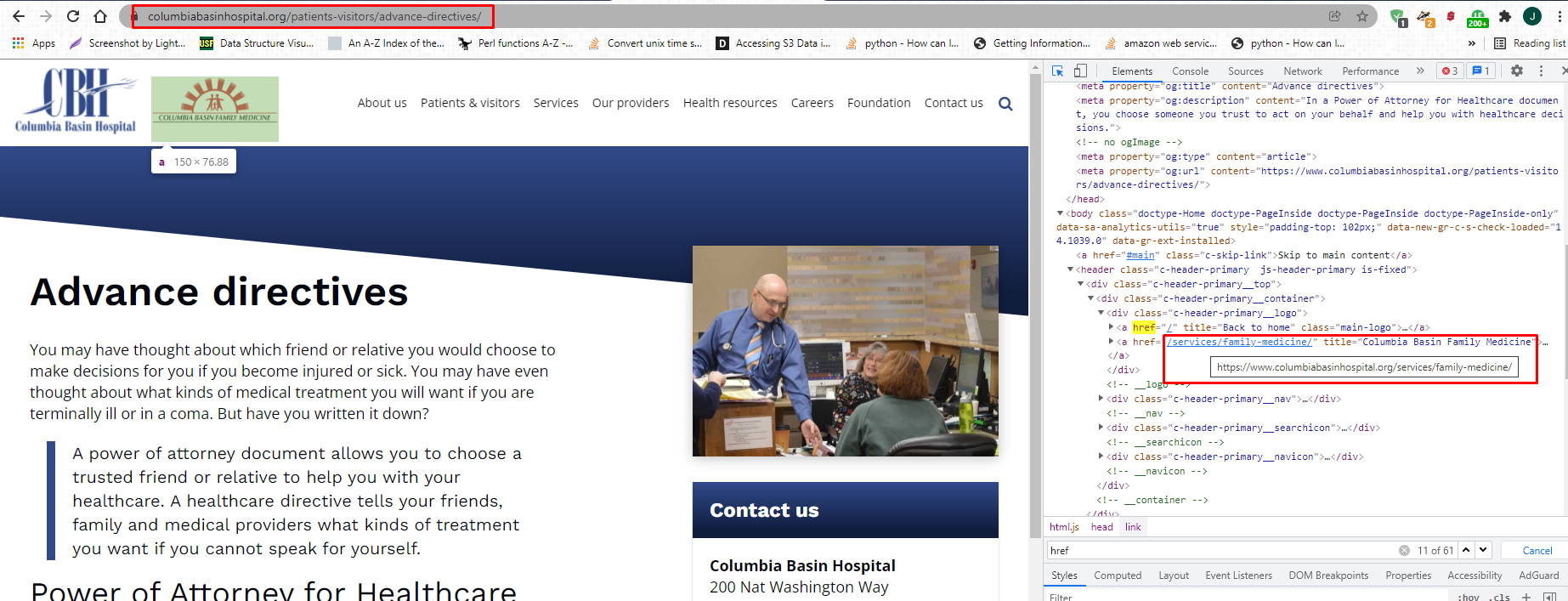
出现了一个我没有意识到的问题。一些路径引用网站上的其他资源。(包括图片)。当前的url是“病人-访客/提前-指令/”,而资源“服务/家庭-医学”实际上指的是columbiabasinhospital.org/services/family-medicine".,我设置它的方式会使资源上的URL (patients-visitors/advance-directives/services/family-medicine). M显示完整的链接。我想知道是否有一种方法可以使用BeautifulSoup检索该链接?谢谢!
Stack Overflow用户
发布于 2021-11-14 07:01:42
您可以使用from urllib.parse import urljoin。但是,你也可以自己写!
假设当前URL为:http://example.com/path1/path2
当href属性的值为:/x时,必须将其添加到根路径,即http://example.com/x
但是,当href属性的值为:./x或x时,需要将其添加到整个地址,即http://example.com/path1/x。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/69960877
复制相关文章
相似问题
腾讯云开发者
