
如何从嵌套的字典键和值列表中生成多索引数据?
如何从嵌套的字典键和值列表中生成多索引数据?
提问于 2021-11-01 12:51:43
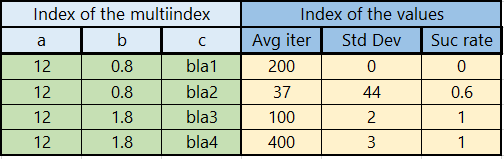
我已经在这里检查过了:Nested dictionary to multiindex dataframe where dictionary keys are column labels,但是我不能让它在我的问题上起作用。我想将字典转换为多索引数据,其中'a','b','c'是多索引的名称,它们的值12,0.8,1.8,bla1,bla2,bla3,bla4是多索引,列表中的值分配给多索引,如下表所示。
我的字典:
dictionary ={
"{'a': 12.0, 'b': 0.8, 'c': ' bla1'}": [200, 0.0, '0.0'],
"{'a': 12.0, 'b': 0.8, 'c': ' bla2'}": [37, 44, '0.6'],
"{'a': 12.0, 'b': 1.8, 'c': ' bla3'}": [100, 2.0, '1.0'],
"{'a': 12.0, 'b': 1.8, 'c': ' bla4'}": [400, 3.0, '1.0']
}我希望得到的结果是DataFrame:
不创建多个索引并在下一行中设置每个值的代码:
df_a = pd.DataFrame.from_dict(dictionary, orient="index").stack().to_frame()
df_b = pd.DataFrame(df_a[0].values.tolist(), index=df_a.index)回答 1
Stack Overflow用户
回答已采纳
发布于 2021-11-01 13:03:06
使用ast.literal_eval将每个字符串转换为一个字典,并从那里构建索引:
import pandas as pd
from ast import literal_eval
dictionary ={
"{'a': 12.0, 'b': 0.8, 'c': ' bla1'}": [200, 0.0, '0.0'],
"{'a': 12.0, 'b': 0.8, 'c': ' bla2'}": [37, 44, '0.6'],
"{'a': 12.0, 'b': 1.8, 'c': ' bla3'}": [100, 2.0, '1.0'],
"{'a': 12.0, 'b': 1.8, 'c': ' bla4'}": [400, 3.0, '1.0']
}
keys, data = zip(*dictionary.items())
index = pd.MultiIndex.from_frame(pd.DataFrame([literal_eval(i) for i in keys]))
res = pd.DataFrame(data=list(data), index=index)
print(res)输出
0 1 2
a b c
12.0 0.8 bla1 200 0.0 0.0
bla2 37 44.0 0.6
1.8 bla3 100 2.0 1.0
bla4 400 3.0 1.0页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/69797193
复制相关文章
相似问题
腾讯云开发者
