
将从另一列到字符串时间列的分钟添加到pyspark中。
将从另一列到字符串时间列的分钟添加到pyspark中。
提问于 2021-09-22 05:41:16
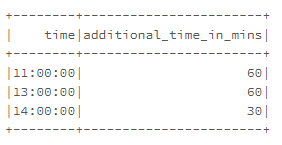
下面有dataframe.both是字符串列。
time additional_time_in_mins
11:00:00 60
13:00:00 60
14:00:00 30我必须将额外时间列中的分钟添加到实际时间中,并创建一个输出,如下所示。
预期产出:
new_time
12:00:00
14:00:00
14:30:00在火星雨中有什么方法可以做到吗?
回答 2
Stack Overflow用户
回答已采纳
发布于 2021-09-22 07:21:14
一个简单的选项是使用time函数在几秒钟内将unix_timestamp列转换为bigint,添加分钟(分钟*60),然后将结果转换回时间戳。
最后,转换为小时格式。
df = df.withColumn('new_time', F.date_format((F.unix_timestamp('time', 'HH:mm:ss') + F.col('additional_time_in_mins')*60).cast('timestamp'), 'HH:mm:ss'))
df.show()
+--------+-----------------------+--------+
| time|additional_time_in_mins|new_time|
+--------+-----------------------+--------+
|11:00:00| 60|12:00:00|
|13:00:00| 60|14:00:00|
|14:00:00| 30|14:30:00|
+--------+-----------------------+--------+Stack Overflow用户
发布于 2021-09-22 07:28:16
使用UDF进行此操作的其他方法:
from pyspark.sql.functions import date_format, col
data = [
("11:00:00", "60"),
("13:00:00", "60"),
("14:00:00", "30"),
]
df = spark.createDataFrame(data, ["time", "additional_time_in_mins"])
df.show()
UDF逻辑求和时间
from pyspark.sql.types import StringType, IntegerType
from pyspark.sql.functions import udf
@udf(returnType=StringType())
def sum_time(var_time, additional_time):
# Converting var_time string to time
var_time = datetime.strptime(var_time, '%H:%M:%S').time()
#Using date to utitlise the time function
combined_time = (datetime.combine(date.today(), var_time) + timedelta(minutes=additional_time)).time()
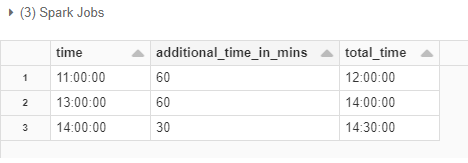
return str(combined_time)使用UDF获得最终输出:
df = df.withColumn(
"total_time", sum_time(col("time"), col("additional_time_in_mins").cast(IntegerType()))
)
display(df)
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/69278747
复制相关文章
相似问题
腾讯云开发者
