
数据工厂数据流(REST到Flatten到Delta) -动态平坦
我有一个非常简单的映射数据流:
- my是一个REST,但是对于所有的目的和目的,您可以想象是一个JSON文件源
- 源JSON有一个类似于
的OData结构
{ "@odata.context":"https://link/api/v1/$metadata#Endpoint1"“,”https://link/api/v1/$metadata#Endpoint1"“:{ "Id":0,"Name":"Email”},{ "Id":1,"Name":"SMS“},{ "Id":2,“名称”:“载体鸽”}
- 扁平化层次结构应按"body.value“动态展开,并以新列的形式检索所有底层节点--在上面的示例中,发送到接收器的列应该是Id,将平面命名为:
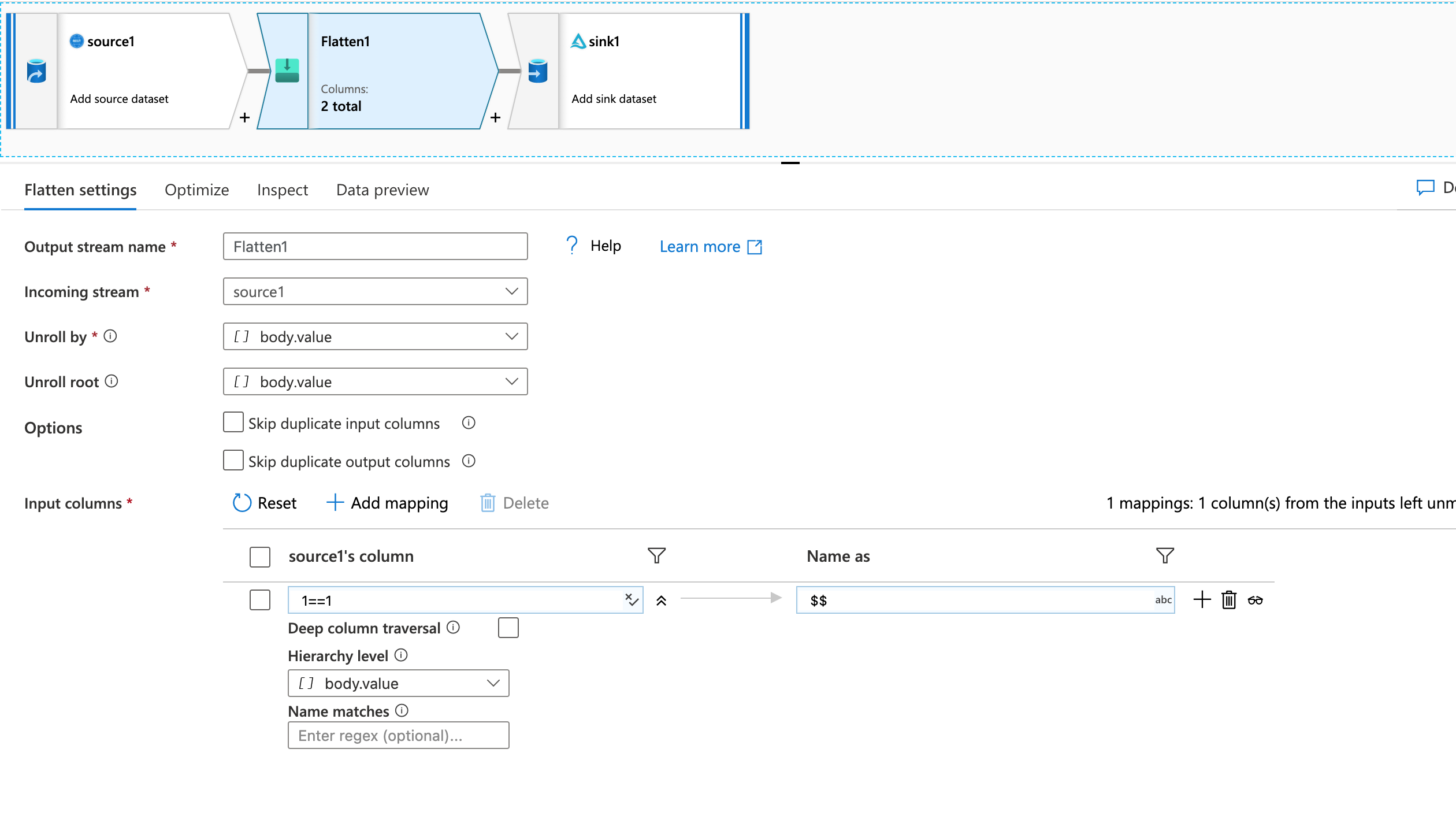
- Sink是ADLSgen2中的Delta表,启用了合并模式:
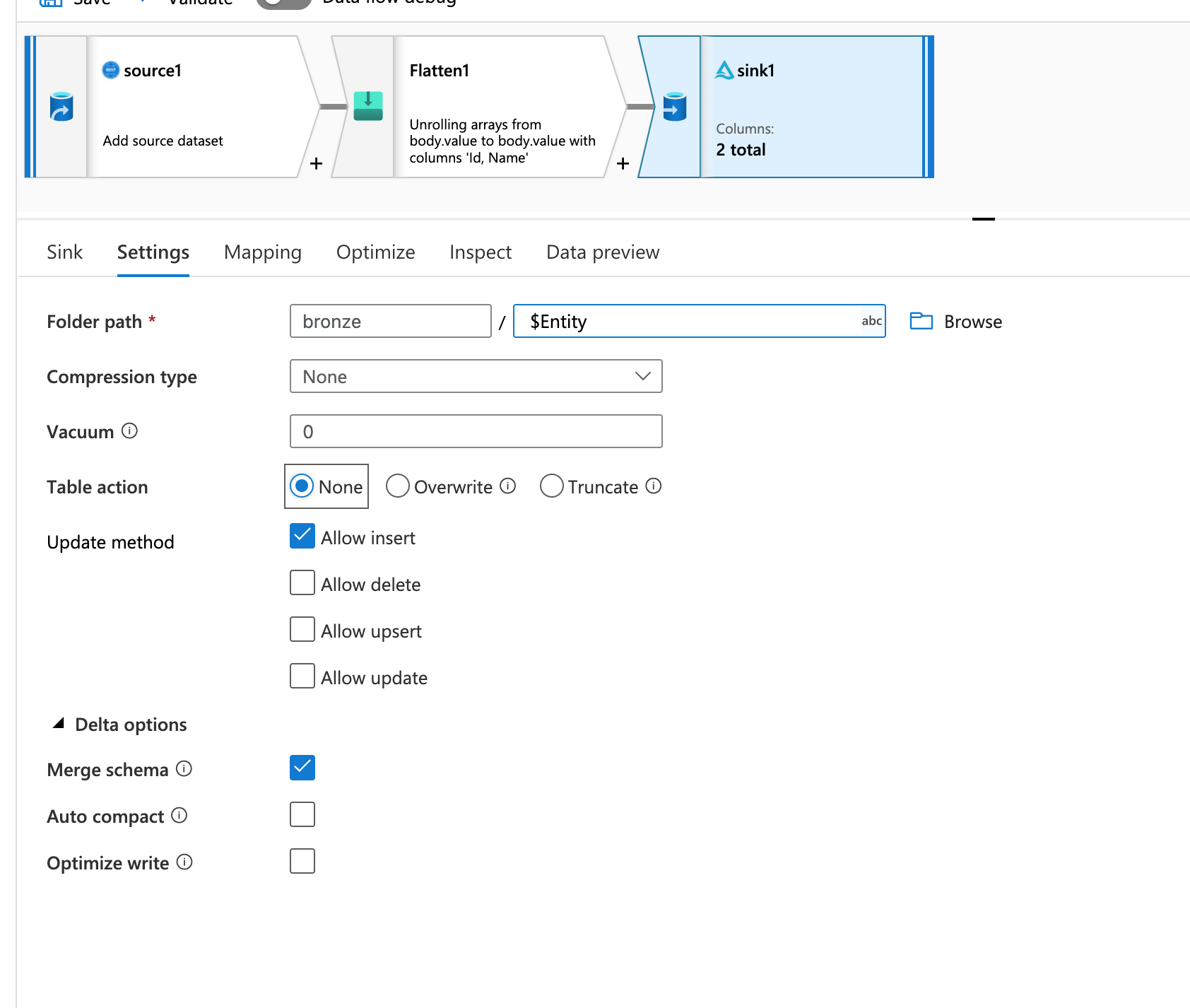
- 上面的数据流将API端点作为参数,并在Foreach活动中为端点列表执行:

- Foreach配置:
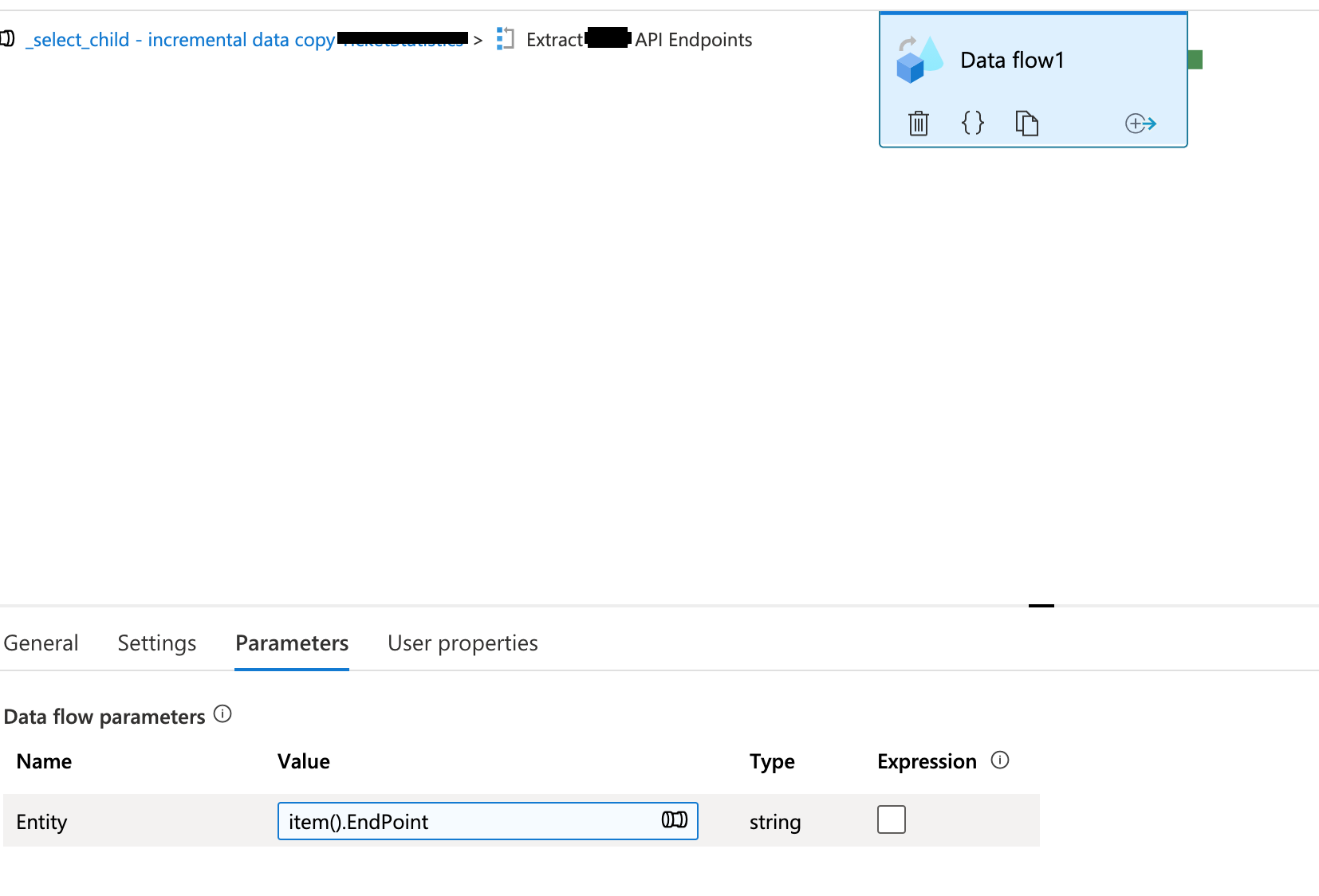
问题是,初始数据流开发中的元数据(列、名称和数据类型)--我使用API端点作为投影模式--是在其他端点执行中保存和传播的。
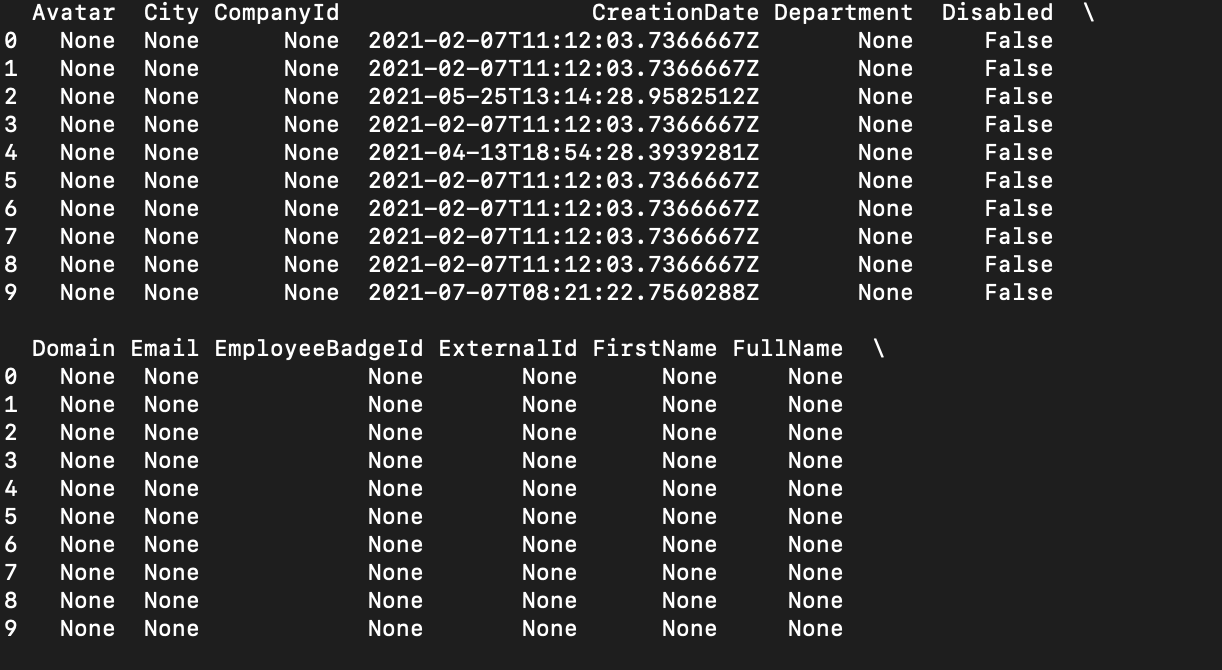
当它正常工作时,我意识到已经加载了端点,但所有来自“模型”端点的列都在当前端点中不存在的列上带有“无”值。这是一个示例,其中CreationDate是一个公共字段,仅在当前端点中禁用,其余的都来自“模型”端点:
另一个例子是,当加载另一个具有不同数据类型Id列的端点时,我遇到了一个数据类型冲突错误:
作业由于原因而失败:在Sink‘Sink 1’:org.apache.spark.sql.AnalysisException:未能合并字段'Id‘和'Id’。未能合并不兼容的数据类型StringType和ShortType;“,StringType未能合并字段'Id‘和'Id’。未能合并不兼容的数据类型StringType和ShortType
我尝试从头创建数据流,而没有在Source投影中导入模式,但是平面转换返回了一个错误--我在平面中使用了"body.value“作为表达式--而且在基于规则的映射中没有”层次级别“的选项:
对目标数据的操作失败:{"StatusCode":"DFExecutorUserError",“Message”:“由于原因而导致作业失败: at FoldDown‘Flatten1’(第14/Col 8行):unrollby应该引用数组或地图列”,“Details”:“}
"body.value“用扁平表示:
如果有人以这种动态的方式成功地使用扁平化,请告诉我你做得如何--我正在努力理解我做错了什么。
回答 1
Stack Overflow用户
发布于 2022-04-11 15:26:10
我也有过类似的问题。我的解决办法是:
- I在扁平之前添加了新列
tempArray的派生列,值为array("1")。在平面中的 - ,然后按
tempArray展开,在层次结构级别使用array("1")。
就像一种魅力。
https://stackoverflow.com/questions/69237904
复制相似问题
腾讯云开发者
