
用笔记本将数据从Azure Synapse数据库加载到DataFrame中
用笔记本将数据从Azure Synapse数据库加载到DataFrame中
提问于 2021-08-17 11:45:56
我试图从Azure Synapse DW中加载数据到一个数据文件中,如图像所示。
但是,我得到了以下错误:
AttributeError: 'DataFrameReader' object has no attribute 'sqlanalytics'
Traceback (most recent call last):
AttributeError: 'DataFrameReader' object has no attribute 'sqlanalytics'
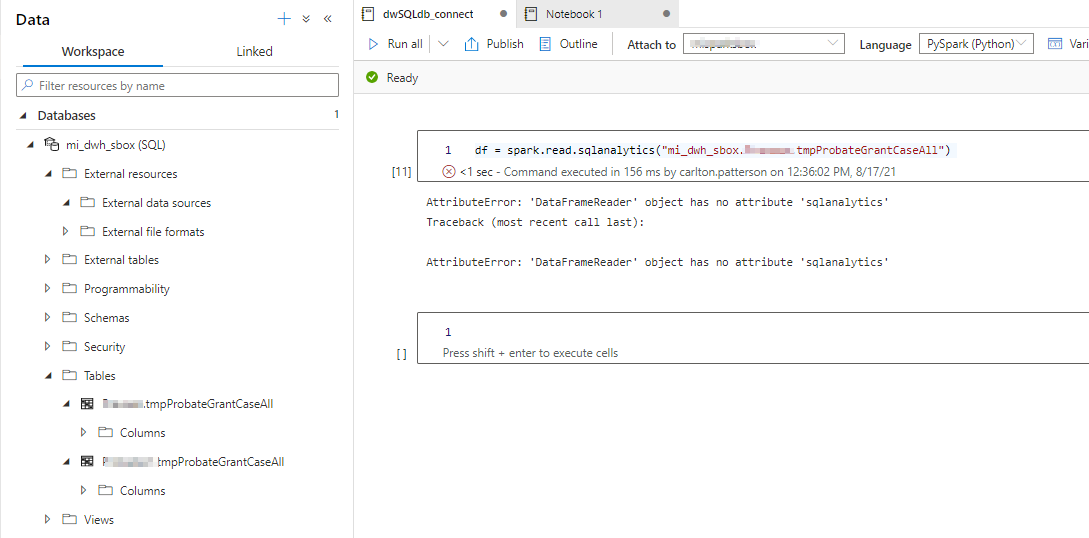
对我做错了什么有什么想法吗?
回答 1
Stack Overflow用户
回答已采纳
发布于 2021-08-17 12:23:22
该特定方法已将其名称更改为synapsesql (根据备注这里),并且只是目前我所理解的Scala。因此,正确的语法是:
%%spark
val df = spark.read.synapsesql("yourDb.yourSchema.yourTable")可以通过createOrReplaceTempView方法与Python共享Scala数据,但我不确定这有多高的效率。对混合与匹配进行了这里描述。因此,对于您的示例,您可以像这样混合和匹配Scala和Python:
细胞1
%%spark
// Get table from dedicated SQL pool and assign it to a dataframe with Scala
val df = spark.read.synapsesql("yourDb.yourSchema.yourTable")
// Save the dataframe as a temp view so it's accessible from PySpark
df.createOrReplaceTempView("someTable")细胞2
%%pyspark
## Scala dataframe is now accessible from PySpark
df = spark.sql("select * from someTable")
## !!TODO do some work in PySpark
## ...上面的链接示例展示了如果需要的话,如何将dataframe写回专用SQL池。
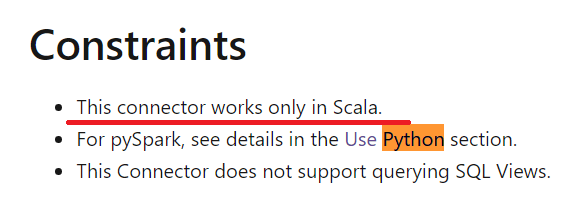
这是一篇很好的文章,用于使用Synpase笔记本导入/导出数据,其限制在约束条件部分中进行了描述:
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/68816778
复制相关文章
相似问题
腾讯云开发者
