
当使用.predict()方法时,sklearn中的管道对象是否转换测试数据?
当使用.predict()方法时,sklearn中的管道对象是否转换测试数据?
提问于 2021-07-07 10:26:23
当我使用管道对象时,
- 当我使用
.fit()方法时,管道对象是否适合并转换的火车数据?或者我应该使用.fit_transform()方法?这两者有什么区别?
- 当我对测试数据使用
.predict()方法时,管道对象是否对测试数据进行转换,然后再进行预测?,也就是说,在使用.predict()方法之前,是否应该使用.transform()方法对测试数据进行转换?
这是我的代码:
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.feature_selection import SelectKBest, f_classif
from sklearn.decomposition import PCA
from sklearn.tree import DecisionTreeClassifier
#creating some data
X, y = np.ones((50, 1)), np.hstack(([0] * 45, [1] * 5))
#creating the pipeline
steps = [('scaler', StandardScaler()), ('SelectKBest', SelectKBest(f_classif, k=3)), ('pca', PCA(n_components=2)), ('DT', DecisionTreeClassifier(random_state=0))]
model = Pipeline(steps=steps)
#splitting the data
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.33, random_state=42)
model.fit(X_train,y_train)
model.predict(X_test)回答 1
Stack Overflow用户
回答已采纳
发布于 2021-07-07 11:27:07
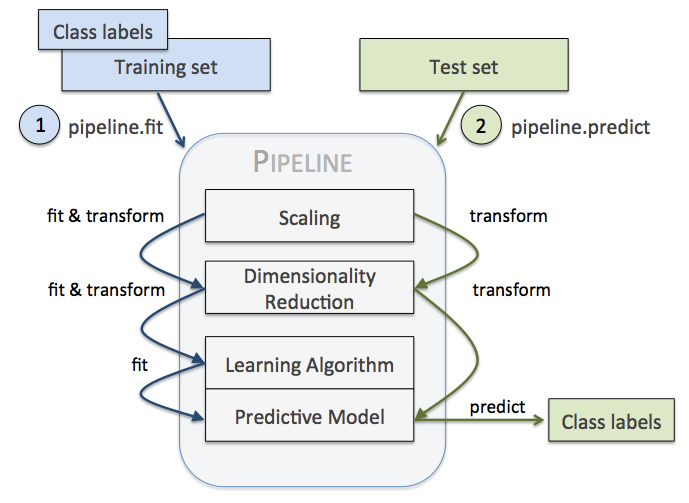
管道对象正在公开其最后一步的方法。由于最后一步是DecisionTreeClassifier (估计器),管道将不具有fit_transform(),而是具有估计器函数,如fit()、predict()、score()等。
当使用fit()时,管道将在所有转换器上调用fit_transform(),最后在估计器上调用fit()。
当使用predict()时,管道将对所有数据进行transform(),然后调用估计器上的predict()。
如图所示:(图片来源: Raschka,Sebastian。Python机器学习。英国伯明翰: Packt出版社,2015年。列印)
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/68284264
复制相关文章
相似问题
腾讯云开发者
