
如何嵌套框图groupBy
如何嵌套框图groupBy
提问于 2021-06-23 10:56:42
我有超过50个特征的数据集,与腿部康复过程中的特定运动相对应。我比较了使用康复装置的组和不使用康复装置的组。该小组包括有3种诊断的病人,我想比较每一次诊断前(红色盒图)和后(蓝盒图)的盒型图。这是我正在使用的片段和我正在获得的输出。
对照组数据:
dataKONTR
Row DG DKK ... LOS_DCL_LB LOS_DCL_L LOS_DCL_LF
0 Williams1 distorze 0.0 ... 63 57 78
1 Williams2 distorze 0.0 ... 91 68 67
2 Norton1 LCA 1.0 ... 58 90 64
3 Norton2 LCA 1.0 ... 29 91 87
4 Chavender1 distorze 1.0 ... 61 56 75
5 Chavender2 distorze 1.0 ... 54 74 80
6 Bendis1 distorze 1.0 ... 32 57 97
7 Bendis2 distorze 1.0 ... 55 69 79
8 Shawn1 AS 1.0 ... 15 74 75
9 Shawn2 AS 1.0 ... 67 86 79
10 Cichy1 LCA 0.0 ... 45 83 80这是我正在使用的片段和我正在获得的输出。
temp = "c:/Users/novos/ŠKOLA/Statistika/data Mariana/%s.xlsx"
dataKU = pd.read_excel(temp % "VestlabEXP_KU", engine = "openpyxl", skipfooter= 85) # patients using our rehabilitation tool
dataKONTR = pd.read_excel(temp % "VestlabEXP_kontr", engine = "openpyxl", skipfooter=51) # control group
dataKU_diag = dataKU.dropna()
dataKONTR_diag = dataKONTR.dropna()
dataKUBefore = dataKU_diag[dataKU_diag['Row'].str.contains("1")] # Patients data ending with 1 are before rehab
dataKUAfter = dataKU_diag[dataKU_diag['Row'].str.contains("2")] # Patients data ending with 2 are before rehab
dataKONTRBefore = dataKONTR_diagL[dataKONTR_diag['Row'].str.contains("1")]
dataKONTRAfter = dataKONTR_diagL[dataKONTR_diag['Row'].str.contains("2")]
b1 = dataKUBefore.boxplot(column=list(dataKUBefore.filter(regex='LOS_RT')), by="DG", rot = 45, color=dict(boxes='r', whiskers='r', medians='r', caps='r'),layout=(2,4),return_type='axes')
plt.ylim(0.5, 1.5)
plt.suptitle("")
plt.suptitle("Before, KU")
b2 = dataKUAfter.boxplot(column=list(dataKUAfter.filter(regex='LOS_RT')), by="DG", rot = 45, color=dict(boxes='b', whiskers='b', medians='b', caps='b'),layout=(2,4),return_type='axes')
# dataKUPredP
plt.suptitle("")
plt.suptitle("After, KU")
plt.ylim(0.5, 1.5)
plt.show()输出为两位数(红色框图全部为“康复前”数据,蓝色盒图全部为“康复后”数据)
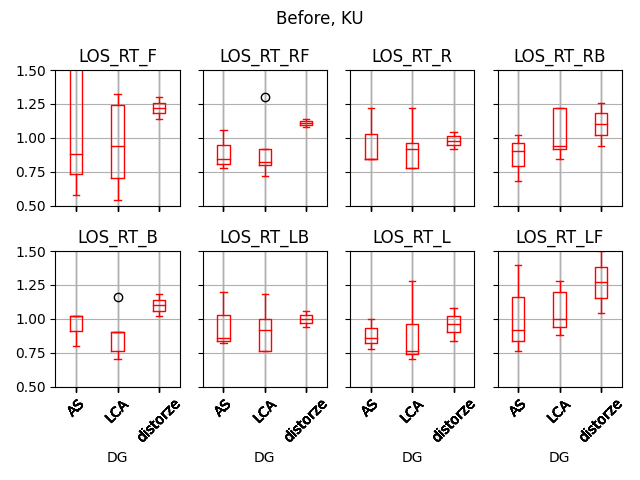
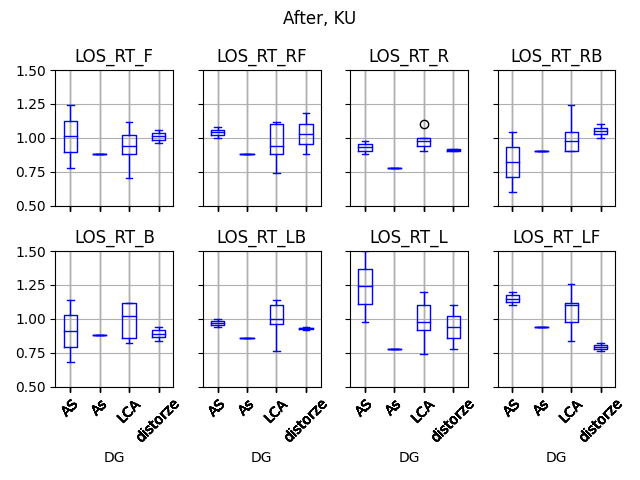
你能帮我把红蓝相间的方格图做好吗?
谢谢你的帮助。
回答 1
Stack Overflow用户
回答已采纳
发布于 2021-06-23 12:38:47
您可以尝试将数据连接到一个数据文件中:
dataKUPlot = pd.concat({
'Before': dataKUBefore,
'After': dataKUAfter,
}, names=['When'])您应该会在输出中看到一个名为When的额外索引级别。使用您发布的示例数据,它如下所示:
>>> pd.concat({'Before': df, 'After': df}, names=['When'])
Row DG DKK ... LOS_DCL_LB LOS_DCL_L LOS_DCL_LF
When
Before 0 Williams1 distorze 0.0 ... 63 57 78
1 Williams2 distorze 0.0 ... 91 68 67
2 Norton1 LCA 1.0 ... 58 90 64
3 Norton2 LCA 1.0 ... 29 91 87
4 Chavender1 distorze 1.0 ... 61 56 75
After 0 Williams1 distorze 0.0 ... 63 57 78
1 Williams2 distorze 0.0 ... 91 68 67
2 Norton1 LCA 1.0 ... 58 90 64
3 Norton2 LCA 1.0 ... 29 91 87
4 Chavender1 distorze 1.0 ... 61 56 75然后,通过修改by石斑鱼,您可以用一个命令来绘制所有的框,从而在相同的图上绘制:
dataKUAfter.boxplot(column=dataKUPlot.filter(regex='LOS_RT').columns.to_list(), by=['DG', 'When'], rot = 45, layout=(2,4), return_type='axes')我相信这是唯一的“简单”方式,恐怕看起来有点困惑:
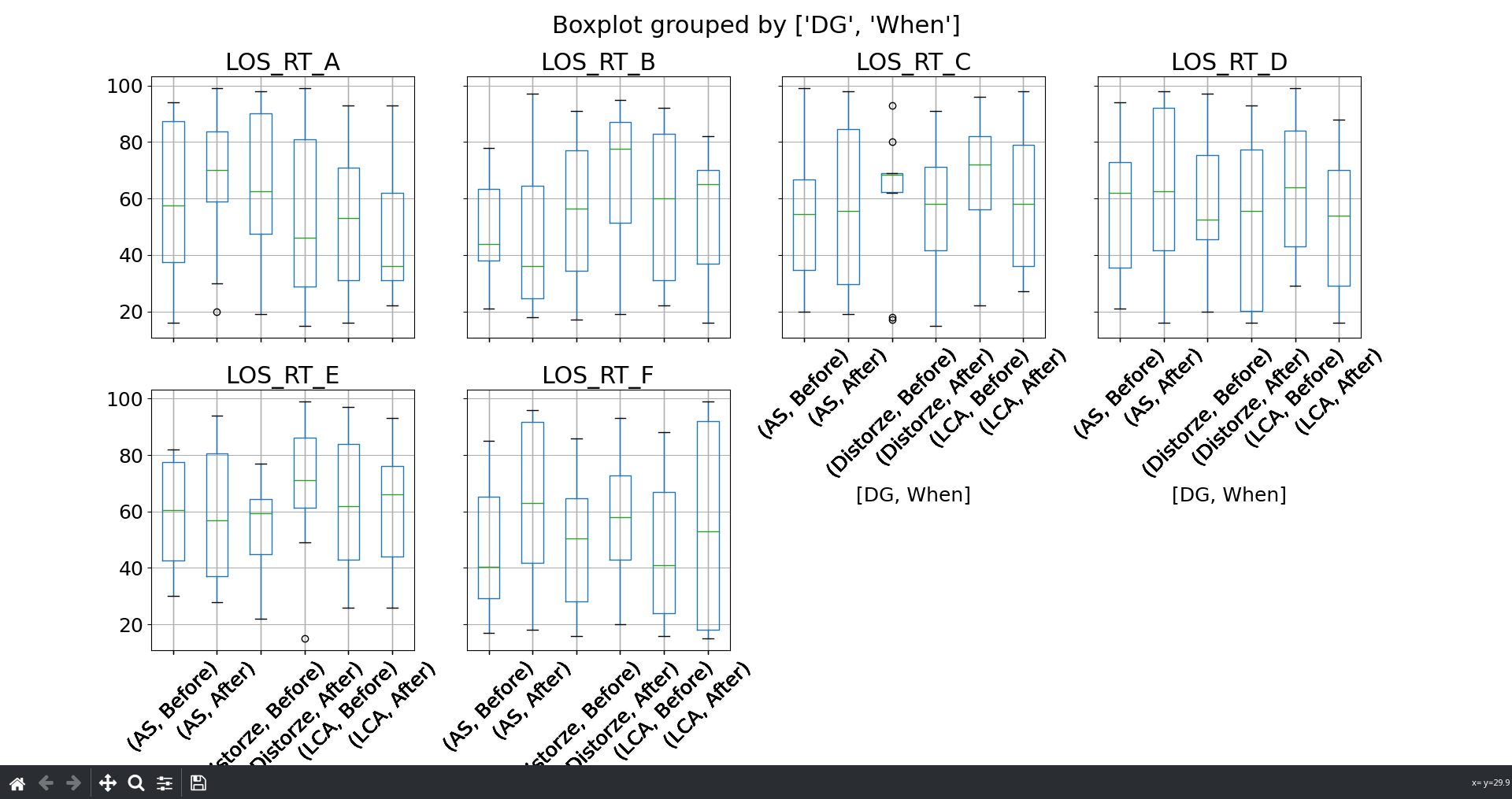
任何其他方法都意味着用matplotlib−手动绘图,从而更好地控制。例如,在所有想要的列上迭代:
fig, axes = plt.subplots(nrows=2, ncols=3, sharey=True, sharex=True)
pos = 1 + np.arange(max(dataKUBefore['DG'].nunique(), dataKUAfter['DG'].nunique()))
redboxes = {f'{x}props': dict(color='r') for x in ['box', 'whisker', 'median', 'cap']}
blueboxes = {f'{x}props': dict(color='b') for x in ['box', 'whisker', 'median', 'cap']}
ax_it = axes.flat
for colname, ax in zip(dataKUBefore.filter(regex='LOS_RT').columns, ax_it):
# Making a dataframe here to ensure the same ordering
show = pd.DataFrame({
'before': dataKUBefore[colname].groupby(dataKUBefore['DG']).agg(list),
'after': dataKUAfter[colname].groupby(dataKUAfter['DG']).agg(list),
})
ax.boxplot(show['before'].values, positions=pos - .15, **redboxes)
ax.boxplot(show['after'].values, positions=pos + .15, **blueboxes)
ax.set_xticks(pos)
ax.set_xticklabels(show.index, rotation=45)
ax.set_title(colname)
ax.grid(axis='both')
# Hide remaining axes:
for ax in ax_it:
ax.axis('off')
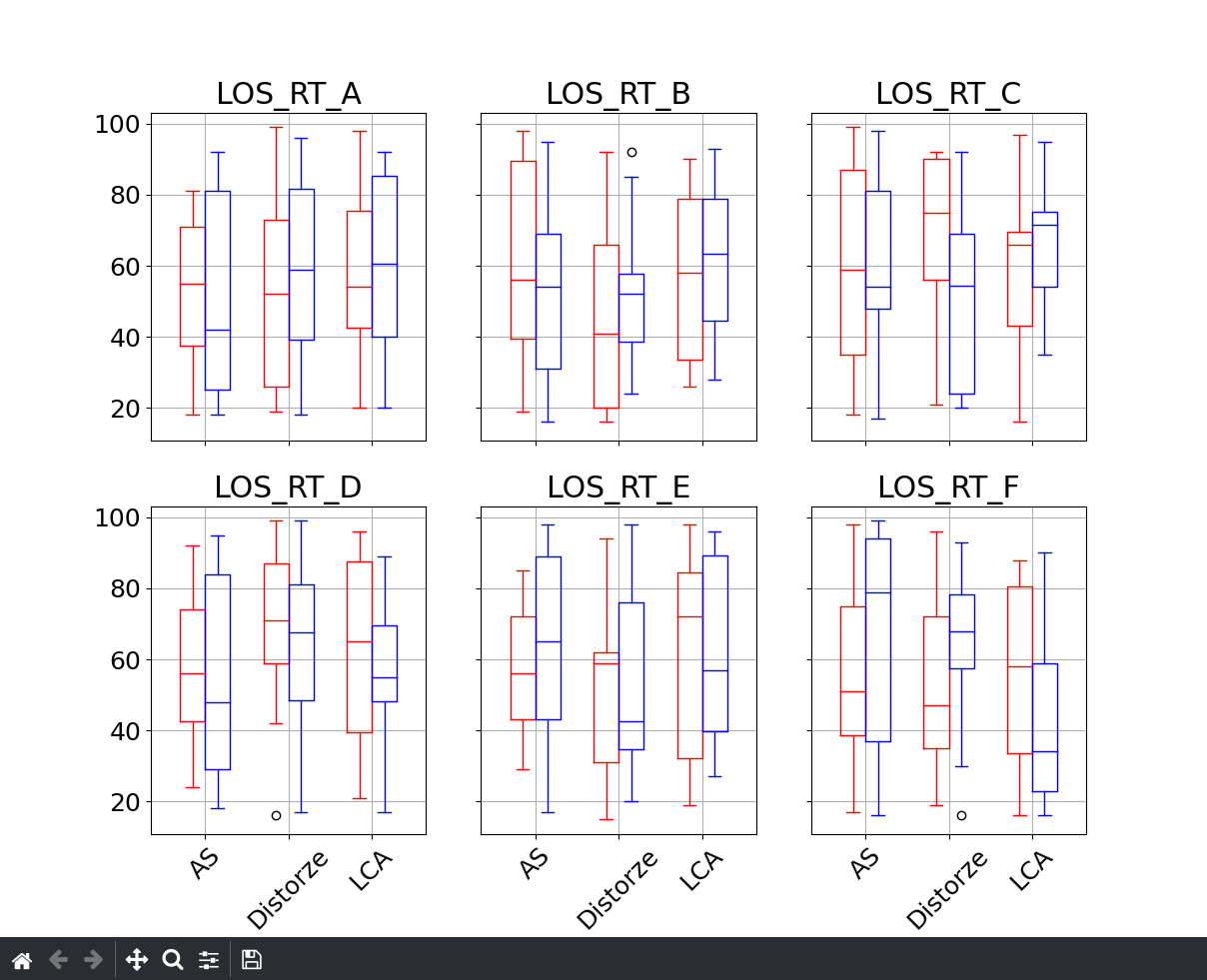
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/68098491
复制相关文章
相似问题
腾讯云开发者
