
多分类和不平衡数据的XGBoost
我正在处理一个3类0,1,2类和不平衡的类分布的分类问题,如下所示。
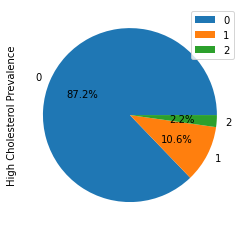
我想将XGBClassifier (在Python中)应用于这个分类问题,但是该模型不响应class_weight的调整并向多数类0倾斜,而忽略了少数类1、2。除了class_weight之外,还有哪些超参数可以帮助我?
我尝试过: 1)使用sklearn compute_class_weight计算类权重;2)根据类的相对频率设置权重;3)手动调整带有极值的类,以查看是否发生了任何更改,如{0:0.5,1:100,2:200}。但在任何情况下,它都无助于分类器考虑到少数群体的类别。
观测:
- --我可以在二进制情况下处理这个问题:如果我通过识别类1、2使问题成为二进制分类,那么我就可以通过调整
scale_pos_weight来使分类器正常工作(即使在这种情况下,class_weight是没有帮助的)。但据我所知,scale_pos_weight适用于二进制分类。对于多分类问题,这个参数有相似之处吗?
- 使用
RandomForestClassifier而不是XGBClassifier,我可以通过设置class_weight='balanced_subsample'和调优max_leaf_nodes来解决问题。但是,由于某些原因,这种方法不适用于XGBClassifier.
。
备注:我知道关于平衡技术的,例如过采样/过采样或击打。但是我想尽可能地避免它们,如果可能的话,我更喜欢使用超参数调优模型的解决方案。我上面的观察表明,这可以适用于二进制情况。
回答 2
Stack Overflow用户
发布于 2021-06-07 10:19:25
sample_weight参数用于处理不平衡的数据,同时使用XGBoost训练数据。您可以使用compute_sample_weight() of sklearn库计算样本权重。
这段代码应该适用于多类数据:
from sklearn.utils.class_weight import compute_sample_weight
sample_weights = compute_sample_weight(
class_weight='balanced',
y=train_df['class'] #provide your own target name
)
xgb_classifier.fit(X, y, sample_weight=sample_weights)Stack Overflow用户
发布于 2022-08-15 12:58:50
您可以像@Prakash建议的那样使用sample_weight,但是可以计算自己的权重。我发现不同的权重产生了巨大的差异(我有12个类,数据非常不平衡)。如果计算自己的权重,则需要为每个条目分配相关的权重,并以相同的方式将param传递给分类器: xgb_class.fit(X_train,y_train,sample_weight=weights)。
https://stackoverflow.com/questions/67868420
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号