
为什么在SQL中使用“小于”的哈希索引速度较慢?
我在大学一级的SQL课程中完成了我的第一个学期,我们使用了第三版的“对凡人的SQL查询”。
长期而言,我想从事数据治理或数据科学家的工作,因此需要更深入地研究,我找到了斯坦福SQL课程。今天参加第一次小测验,我得到了正确的答案,但在这两个问题上,我不明白为什么我得到了正确的答案。
我的“纯粹是凡人的SQL”一书甚至没有涵盖基于哈希或基于树的索引,所以我一直在网上搜索它们。
我主要是根据她的话猜测,但感觉更像是运气,而不是“我很清楚为什么”。所以我订购了托马斯·科门的第三版“算法导论”,并于上周面世,但我需要一段时间才能阅读完所有的1229页。
在另一个堆栈溢出链接=>https://stackoverflow.com/questions/66515417/why-is-hash-function-fast中找到了那本书
斯坦福课程=> https://www.edx.org/course/databases-5-sql
我认为College.enrollment上的散列索引不会加速,因为他们将其限制为小于一个数字与实际数字?我猜根据这个链接最好在sql查询中使用“小于等于”或" in“。,如果我们使用"<=“而不是"<”,查询会更快?
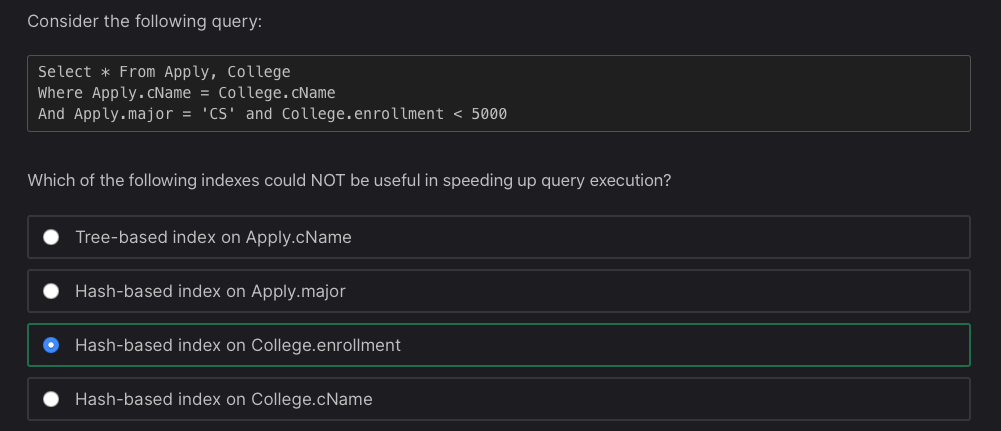
这个过程只是一个消除的过程,因为它提到WHERE子句之后的第一个项目,但是当它提到Apply.cName = College.cName的最后一部分时却很混乱。
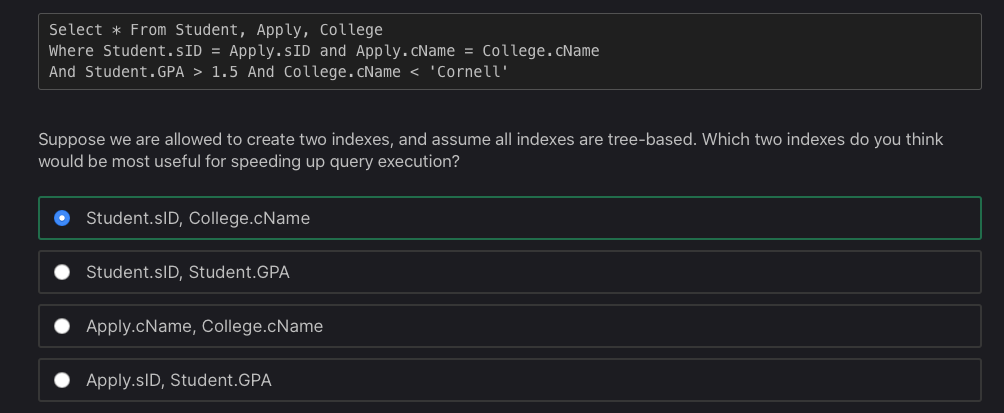
我的问题:
- 我猜想,类似于代数,有分子和分母,商,和许多其他术语,具体描述了一个方程的一部分使用技术术语。你如何用技术术语来描述为什么这些答案是正确的。
- 关于第二个问题,为什么第二行的第一部分被引用,同一行的最后一部分被引用作为答案。为什么他们不选择每一部分最后一部分的第一部分?
对于上下文,我的大多数SQL查询都是为PostgreSQL编写的,现在是在PyCharm中编写的,但我使用PgAgmin4或MySqlWorkbench桌面平台进行了大量实践。
我欢迎您在纸质书或pdf上的任何建议,它们都有一步一步的教程,因为很多网站都有漏洞或参考技术细节,令人困惑。
谢谢
回答 2
Stack Overflow用户
发布于 2021-06-03 22:22:44
哈希索引仅适用于相等匹配,而树索引可用于不平等(** >= <**或等)。
考虑到这一点,College.enrollment < 5000不能使用散列索引,因为它是一个不等式。所有其他选项都是完全相等的匹配。
这就是为什么大多数RDBMS只允许您创建基于树的索引。
2.这个几乎是在空中。。
“WHERE子句之后的第一项”与此无关。大多数RDBMS将根据它们认为适合的情况重新排序联接和筛选器,以便匹配索引和表统计信息。
--我注意到,给出的查询写得很糟糕,应该使用正确的JOIN语法,这要清楚得多,并且已经使用了30年。
SELECT * -- you should really specify exact columns
FROM Student AS s -- use aliases
JOIN [Apply] AS a ON a.sID = s.sID -- Apply is a reserved keyword in many RDBMS
JOIN College AS c ON c.cName = a.aName
WHERE s.GPA > 1.5 AND c.cName < 'Cornell';现在很难说编译器会在这里做什么。这在很大程度上取决于基数(表的大小)的绝对值和相对值,以及s.GPA和c.cName中的数据倾斜。
这还取决于是否添加了辅助键(或实际上是INCLUDE)列,显然没有考虑到这一点。
给出了上述索引的选项,并且没有其他索引(显然不现实),我们可以猜测:
Student.sID, College.cName这可能导致从College开始对'Cornell'进行高效的反向扫描,但是Apply需要使用哈希或简单的嵌套循环(每次扫描索引)进行连接。Student上的索引意味着具有索引查找的高效嵌套循环。Student.sID, Student.GPA这是一个索引还是两个索引?如果它是两个单独的索引,那么第二个将被使用,而第一个显然是无用的。Apply和College仍然需要大量的连接。Apply.cName, College.cName这可能会在这两列上得到一个合并连接,但是Student需要一个大的连接。Apply.sID, Student.GPAStudent可以从1.5中高效地扫描,Apply可以被查找,但是College需要一个大的连接。
在这些选项中,第一种或最后一种可能更好,但如果没有更多的信息,很难说出来。
在实际系统中,我将对所有表进行索引,并明智地使用INCLUDE列,以避免查找键。您可能希望更好地了解哪些表需要提前过滤,等等。
Stack Overflow用户
发布于 2021-06-03 22:23:04
第一个问题
散列索引不是线性搜索的。 (参见幻灯片7),也就是说,您不能使用散列索引执行范围比较.这是因为(一般说来)哈希函数是单向的:给定哈希函数的输出,您无法确定输入,并且输出将以明显的随机顺序(具有随机顺序有助于确保哈希表回收箱上的均匀负载)。
现在,对于一个经过精心设计和过度简化的例子:
假设您有以下几行:
PK | Enrollment
----------------
1 | 1
2 | 10
3 | 100
4 | 1000
5 | 10000该表的完美哈希索引如下所示:
假设1的哈希为0xF822AA896F34253E,而10的哈希为0xB383A8BBDAA41F98,依此类推.
EnrollmentHash | PhysicalRowPointer
---------------------------------------
0xF822AA896F34253E | 1
0xB383A8BBDAA41F98 | 2
0xA60DCD4E78869C9C | 3
0x49B0AF769E6B1EB3 | 4
0x724FD1728666B90B | 5因此,给定此哈希表索引,查看哈希,您无法确定哪个哈希表示更大的注册值和较小的值。但是哈希表索引确实为您提供了对单个特定值的O(1)查找,这就是为什么它对离散的、非连续的数据值,特别是JOIN标准中使用的列最有效的原因。
虽然树哈希确实保留了有关值的相对排序信息,但是使用了O( log n )查找时间。
第二个问题
首先,我需要重写查询以使用现代的JOIN语法。旧的风格(使用逗号)从1992年的SQL92开始就已经过时了,那是30年前的事了。
SELECT
*
FROM
Apply
INNER JOIN Student ON Student.sID = Apply.sID
INNER JOIN College ON Apply.cName = Apply.cName
WHERE
Student.GPA > 1.5
AND
College.cName < 'Cornell'现在,一般来说,回答这类问题的最好方法是知道表的STATISTICS (基数、值分布等)是什么。但没有这些,我还能猜到一些。
我假设College是最小的表(~500行?),Student可能有120万行,假设每个学生都提出4-5个应用程序,那么Apply表将有大约5M行。
...armed通过这个推论,我们可以推断出:
Student.sID = Apply.sID是一个ID匹配所以在大多数情况下哈希索引会更好(除非PK集群很重要,但我不会离题)。Student.GPA > 1.5-这是一个范围搜索,所以这里有一个基于树的索引有帮助。College.cName < 'Cornell'--同样,这是一个范围比较,所以这里基于树的索引也有帮助。
所以最好的索引应该是Student.GPA和College.cName,但是这不是一个选项,所以让我们看看每个选项的好处是什么……
(当我写这篇文章时,我看到@charlieface发布了他们的答案,其中已经包括了这一点,所以我只需链接到他们的答案,以节省我的时间:https://stackoverflow.com/a/67829326/159145 )
https://stackoverflow.com/questions/67829047
复制相似问题
腾讯云开发者
