
输入spark.sql.autoBroadcastJoinThreshold .?
输入spark.sql.autoBroadcastJoinThreshold .?
提问于 2021-05-28 07:41:41
大概我可以在SparkVersion3.1.1中找到一个错误。我正在使用ScalaVersion2.12.10 (OpenJDK 64位服务器VM,Java11.0.11)
scala> spark.conf.get("spark.sql.autoBroadcastJoinThreshold")
res0: String = 10485760b但应该是: 104857600。
因此:
scala> spark.conf.set("spark.sql.autoBroadcastJoinThreshold", 104857600)当您使用"10485760b“进行部署时,Spark无法检测到已加入的DataFrames中有一个是小的(默认为10 MB )。可以禁用自动广播连接检测的阈值。我希望我的评论能帮到别人?
回答 1
Stack Overflow用户
发布于 2021-05-28 08:30:45
这不是一个错误,而是一个正确的值。
根据有关星火配置的文档,autoBroadcastJoinThreshold的默认值为10 as,定义为
“为执行联接时将广播到所有工作节点的表配置最大大小(以字节为单位)。”
您建议的104857600值将导致104857600 / 1024 / 1024 = 100MB,这可能会对应用程序性能的健康造成损害。
此外,在文档的开始中,它解释了"b“代表什么:
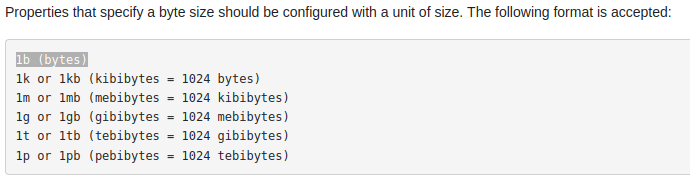
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/67734782
复制相关文章
相似问题
腾讯云开发者
