
在R中将自由住宅索引转换成整洁的格式
在R中将自由住宅索引转换成整洁的格式
提问于 2021-05-25 07:23:15
正如标题所述,我想把自由之家索引从excel转换成整洁的R格式。FHI可以在https://freedomhouse.org/reports/publication-archives下下载,然后在1973-2021年国家和地区的评级和地位下下载,看起来如下:excel中的FHI。
{kind=link}
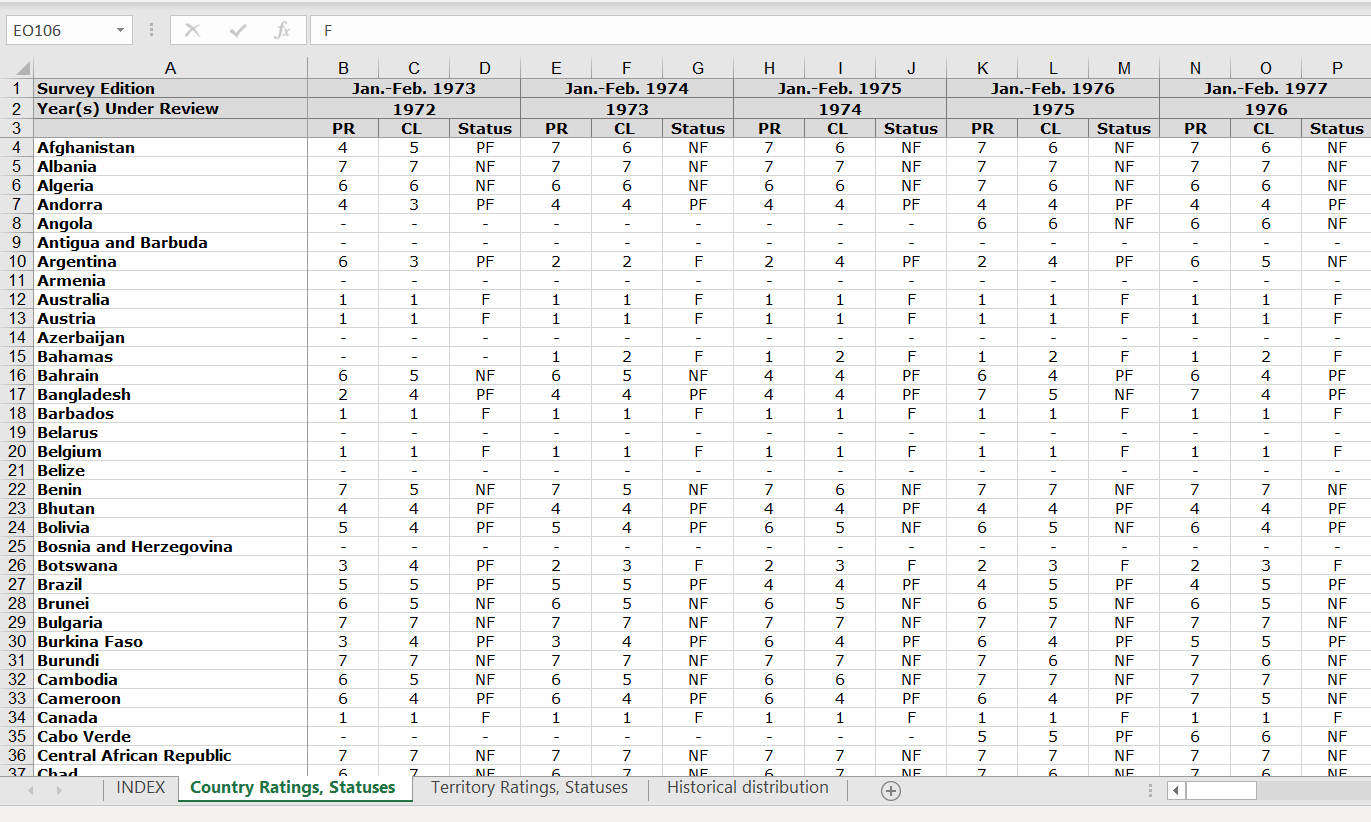
我已经用下面的代码完成了它,但是我认为我的解决方案不是很优雅,更像是分解和处理。因此,我正在寻找另一个解决方案,充其量在潮间带内。提前谢谢。
#load packages
library(tidyverse)
#load data
library(readxl)
fh <- read_excel("Data/Country_and_Territory_Ratings_and_Statuses_FIW1973-2021.xlsx",
sheet = "Country Ratings, Statuses ",
col_names = FALSE, na = "-")
# remove survey edition and years
fh_raw <- fh %>%
filter(...1 != c("Survey Edition",
"Year(s) Under Review"))
# save country names
cty <- unlist(fh_raw[1]) %>%
unname()
fh_raw <- fh_raw %>%
select(!...1)
# variable
pr <- seq(to = length(fh_raw), by = 3)
cl <- seq(from = 2, to = length(fh_raw), by = 3)
status <- seq(from = 3, to = length(fh_raw), by = 3)
# select variables and transform into long-format
fh_pr <- fh_raw[pr] %>%
pivot_longer(cols = 1:length(pr))
fh_pr <- unlist(fh_pr[2]) %>%
unname() %>% as.numeric()
fh_cl <- fh_raw[cl] %>%
pivot_longer(cols = 1:length(cl))
fh_cl <- unlist(fh_cl[2]) %>%
unname() %>% as.numeric()
fh_status <- fh_raw[status] %>%
pivot_longer(cols = 1:length(status))
fh_status <- unlist(fh_status[2]) %>%
unname()
cty <- rep(cty, each = length(cl))
year = 1972:2020
year <- rep(year[year != 1981], times = 205) # 1981 is skipped
#create FH data frame
fh_long <- tibble(country = cty,
year = year,
pr = fh_pr,
cl = fh_cl,
status = fh_status)回答 1
Stack Overflow用户
回答已采纳
发布于 2021-05-25 11:47:35
进入tidyxl和unpivotr的神奇世界;-)
library(tidyverse)
library(tidyxl)
library(unpivotr)
file.to.read <- "./Country_and_Territory_Ratings_and_Statuses_FIW1973-2021.xlsx"
sheet.to.read <- "Country Ratings, Statuses "
#read sheet's contents (take a look at it to see what you actrually just read in)
cells <- tidyxl::xlsx_cells( file.to.read, sheet = sheet.to.read)
ans <- cells %>%
# Drop empty cells
dplyr::filter(!is_blank) %>%
# Setup headers from top and left side
unpivotr::behead("up", "Survey_Edition") %>%
unpivotr::behead("up", "year") %>%
unpivotr::behead("up", "item") %>%
unpivotr::behead("left", "country") %>%
# There are unwanted training spaces in the item-clum, remove them
dplyr::mutate(item = trimws(item)) %>%
# Get value from numeric and character-column
dplyr::mutate(value = ifelse(item == "Status", character, numeric)) %>%
# Drop unneeded data
dplyr::select(country, year, item, value) %>%
# Fill down missing year info
tidyr::fill(year, .direction = "down") %>%
# Cast to wide format
tidyr::pivot_wider(names_from = item, values_from = value)输出
# country year PR CL Status
# <chr> <chr> <chr> <chr> <chr>
# 1 Afghanistan 1972 4 5 PF
# 2 Afghanistan 1973 7 6 NF
# 3 Afghanistan 1974 7 6 NF
# 4 Afghanistan 1975 7 6 NF
# 5 Afghanistan 1976 7 6 NF
# 6 Afghanistan 1977 6 6 NF
# 7 Afghanistan 1978 7 7 NF
# 8 Afghanistan 1979 7 7 NF
# 9 Afghanistan 1980 7 7 NF
#10 Afghanistan Jan.1981-Aug. 1982 7 7 NF
#11 Afghanistan Aug.1982-Nov.1983 7 7 NF
#12 Afghanistan Nov.1983-Nov.1984 7 7 NF
#13 Afghanistan Nov.1984-Nov.1985 7 7 NF
#14 Afghanistan Nov.1985-Nov.1986 7 7 NF
#15 Afghanistan Nov.1986-Nov.1987 7 7 NF
#16 Afghanistan Nov.1987-Nov.1988 6 6 NF
#17 Afghanistan Nov.1988-Dec.1989 7 7 NF
#18 Afghanistan 1990 7 7 NF
#19 Afghanistan 1991 7 7 NF
#20 Afghanistan 1992 6 6 NF
# ...页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/67683442
复制相关文章
相似问题
腾讯云开发者
