
SGD分类器精度-召回曲线
我正在研究一个二进制分类问题,我有一个sgd分类器,如下所示:
sgd = SGDClassifier(
max_iter = 1000,
tol = 1e-3,
validation_fraction = 0.2,
class_weight = {0:0.5, 1:8.99}
)我把它安装在我的训练集上,并绘制了精确召回曲线:
from sklearn.metrics import plot_precision_recall_curve
disp = plot_precision_recall_curve(sgd, X_test, y_test)
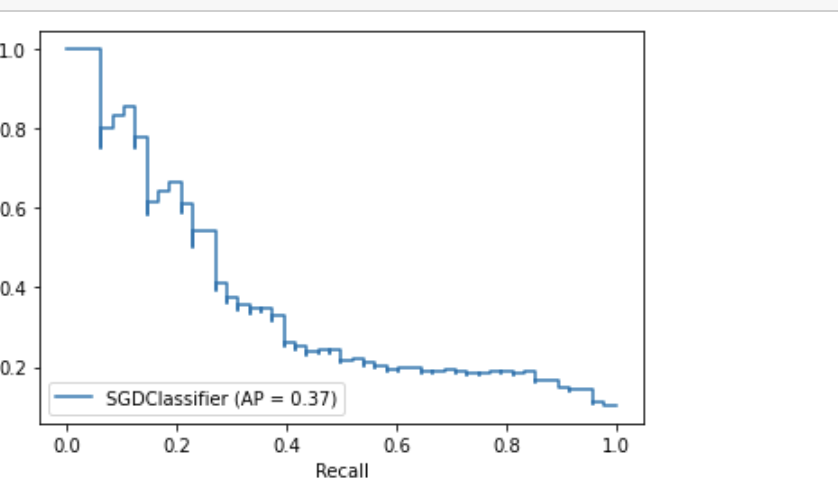
假设scikit学习中的sgd分类器默认使用loss="hinge",如何绘制这条曲线?我的理解是sgd的输出不是概率的-它要么是1/0。因此,没有“阈值”,然而,雪橇精确-回忆曲线绘制了一个具有不同类型阈值的锯齿形图。这里发生了什么事?
回答 1
Stack Overflow用户
发布于 2021-05-09 19:09:13
您描述的情况实际上与文档示例中使用的前2类虹膜数据和一个LinearSVC分类器中的情况相同(该算法使用平方铰链丢失,这与您在这里使用的铰链丢失一样,导致一个分类器只产生二进制结果,而不是概率结果)。由此产生的阴谋是:
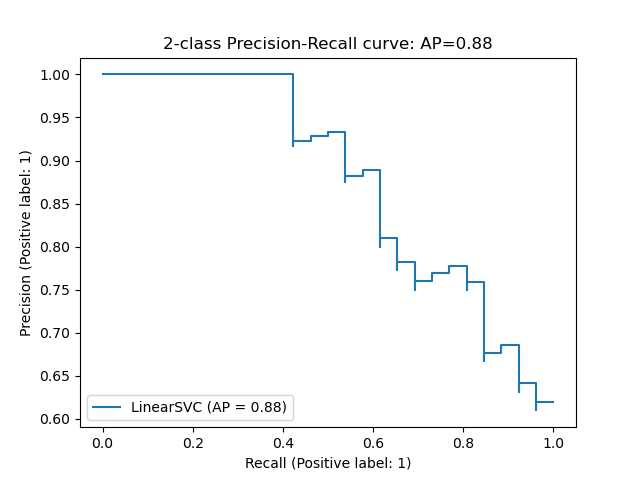
在质量上和你的很相似。
尽管如此,你的问题是合理的,也是一个不错的陷阱;当我们的分类器不产生概率预测(因此任何阈值的概念听起来都不相关)时,我们怎么会得到类似概率分类器产生的行为呢?
为了了解为什么会这样,我们需要从这里使用的plot_precision_recall_curve函数开始,然后沿着线程向下深入到兔子洞.
从源代码 of plot_precision_recall_curve开始,我们发现:
y_pred, pos_label = _get_response(
X, estimator, response_method, pos_label=pos_label)因此,为了绘制PR曲线,预测y_pred不是由我们的分类器的predict方法直接生成的,而是由scikit-learn的_get_response()内部函数生成的。
_get_response()依次包括以下几行:
prediction_method = _check_classifier_response_method(
estimator, response_method)
y_pred = prediction_method(X)这最终将我们引向_check_classifier_response_method()内部函数;您可以检查它的完整源代码 --这里感兴趣的是else语句之后的以下3行:
predict_proba = getattr(estimator, 'predict_proba', None)
decision_function = getattr(estimator, 'decision_function', None)
prediction_method = predict_proba or decision_function到现在为止,您可能已经开始了解问题了:在遮罩下,plot_precision_recall_curve检查所使用的分类器是否可用predict_proba()或decision_function()方法;如果没有predict_proba(),比如有铰链丢失的SGDClassifier (或具有平方铰链损失的LinearSVC分类器的文档示例 ),它将恢复到decision_function()方法,以便计算随后将用于绘制PR (和ROC)曲线的y_pred。
上述问题可以说回答了您的编程问题,即在这种情况下,scikit-learn是如何生成绘图和基本计算的;关于是否和为什么使用非概率分类器的decision_function()确实是获得PR (或ROC)曲线的正确和合法方法的进一步的理论询问是不可能的,如果有必要的话,它们应该被发送到交叉验证。
https://stackoverflow.com/questions/67460329
复制相似问题
腾讯云开发者
