
如何根据python中的两个不同列(不使用循环)获取每个行对象的转换字符串?
如何根据python中的两个不同列(不使用循环)获取每个行对象的转换字符串?
提问于 2021-04-29 11:45:48
我有以下数据结构:
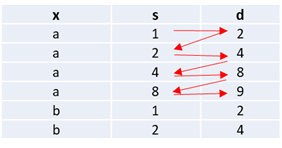
列s和d表示x列中对象的转换。我要做的是获取列x中每个对象的转换字符串。例如,对于新列,如下所示:
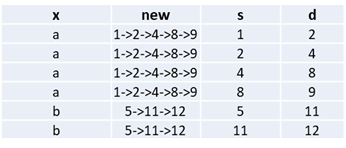
有没有一种不需要太多循环就可以利用熊猫的精益方法呢?
这是我试过的代码:
obj = df['x'].tolist()
rows = []
for o in obj:
locs = df[df['x'] == o]['s'].tolist()
str_locs = '->'.join(str(l) for l in locs)
print(str_locs)
d = dict()
d['x'] = o
d['new'] = str_locs
rows.append(d)
tmp = pd.DataFrame(rows)这给出了输出温度如下:
x new
a 1->2->4->8
a 1->2->4->8
a 1->2->4->8
a 1->2->4->8
b 1->2
b 1->2回答 1
Stack Overflow用户
回答已采纳
发布于 2021-04-29 13:21:12
示例df:
df = pd.DataFrame({"x":["a","a","a","a","b","b"], "s":[1,2,4,8,5,11],"d":[2,4,8,9,11,12]})
print(df)
x s d
0 a 1 2
1 a 2 4
2 a 4 8
3 a 8 9
4 b 5 11
5 b 11 12下面的代码将生成列x中所有对象的转换字符串。
groupby关于x- Merge中每个可用对象的x和列表列表( of ‘s和d )列表sequentially
- Remove 连续重复的
E 223从E 124合并列表e 225/code>使用itertools.groupby Join将合并列表中的项与E 131->E 232合并成一个string.Finally映射。df
输入的列x系列
from itertools import groupby
grp = df.groupby('x')[['s', 'd']].apply(lambda x: x.values.tolist())
grp = grp.apply(lambda x: [str(item) for tup in x for item in tup])
sr = grp.apply(lambda x: "->".join([i[0] for i in groupby(x)]))
df["new"] = df["x"].map(sr)
print(df)
x s d new
0 a 1 2 1->2->4->8->9
1 a 2 4 1->2->4->8->9
2 a 4 8 1->2->4->8->9
3 a 8 9 1->2->4->8->9
4 b 5 11 5->11->12
5 b 11 12 5->11->12页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/67316741
复制相关文章
相似问题
腾讯云开发者
