
如何计算excel中数据之间发生的次数?
如何计算excel中数据之间发生的次数?
提问于 2021-04-26 22:39:43
我有一个由数千个数据组成的巨大的CSV表,我想把两个元素的出现数除以该元素的数量[

像一样,比特币在这一行中出现了8次,用 API 出现了2次,所以比特币与API之间的关系是:API总是与比特币一起存在,所以APIe 210出现在比特币中的值是1,而比特币出现在API中的值是1/4。
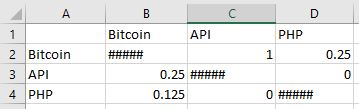
我如何使用python或其他任何工具来完成它呢?
这是文件的示例
回答 2
Stack Overflow用户
回答已采纳
发布于 2021-04-26 23:09:57
这个,我想,确实是这样的。我用手将您的电子表格输入到csv中(如果能够剪切和粘贴会很好),结果似乎是合理的。
import itertools
import csv
import numpy as np
words = {}
for row in open('input.csv'):
parts = row.rstrip().split(',')
for a,b in itertools.combinations(parts,2):
if a not in words:
words[a] = [b]
else:
words[a].append( b )
if b not in words:
words[b] = [a]
else:
words[b].append( a )
print(words)
size = len(words)
keys = list(words.keys())
track = np.zeros((size,size))
for i,k in enumerate(keys):
track[i,i] = len(words[k])
for j in words[k]:
track[i,keys.index(j)] += 1
track[keys.index(j),i] += 1
print(keys)
# Scale to [0,1].
for row in range(track.shape[0]):
track[row,:] /= track[row,row]
# Create a csv with the results.
fout = open('corresp.csv','w')
print( ','.join([' ']+keys), file=fout )
for row in range(track.shape[0]):
print( keys[row], file=fout, end=',')
print( ','.join(f"{track[row,i]}" for i in range(track.shape[1])), file=fout )下面是结果的前几行:
,API,Backend Development,Bitcoin,Docker,Article Rewriting,Article writing,Blockchain,Content Writing,Ghostwriting,Android,Ethereum,PHP,React.js,C Programming,C++ Programming,ASIC,Digital ASIC Coding,Embedded Software,Article Writing,Blog,Copy Typing,Affiliate Marketing,Brand Marketing,Bulk Marketing,Sales,BlockChain,Business Strategy,Non-fungible Tokens,Technical Writing,.NET,Arduino,Software Architecture,Bluetooth Low Energy (BLE),C# Programming,Ada programming,Programming,Haskell,Rust,Algorithm,Java,Mathematics,Machine Learning (ML),Matlab and Mathematica,Data Entry,HTML,Circuit Designs,Embedded Systems,Electronics,Microcontroller, C++ Programming,Python
API,1.0,0.14285714285714285,0.5714285714285714,0.14285714285714285,0.0,0.0,0.2857142857142857,0.0,0.0,0.0,0.14285714285714285,0.0,0.14285714285714285,0.2857142857142857,0.2857142857142857,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0
Backend Development,0.6666666666666666,1.0,0.6666666666666666,0.6666666666666666,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0
Bitcoin,0.21052631578947367,0.05263157894736842,1.0,0.05263157894736842,0.0,0.0,0.2631578947368421,0.0,0.0,0.05263157894736842,0.10526315789473684,0.10526315789473684,0.05263157894736842,0.15789473684210525,0.21052631578947367,0.05263157894736842,0.05263157894736842,0.05263157894736842,0.0,0.0,0.0,0.05263157894736842,0.05263157894736842,0.05263157894736842,0.05263157894736842,0.05263157894736842,0.05263157894736842,0.05263157894736842,0.05263157894736842,0.0,0.0,0.05263157894736842,0.0,0.0,0.0,0.0,0.05263157894736842,0.05263157894736842,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0
Docker,0.6666666666666666,0.6666666666666666,0.6666666666666666,1.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0Stack Overflow用户
发布于 2021-04-27 02:36:50
我在Excel中创建了一个枢轴表,用于每个列的组合: AB AC、AD、BC、BD、CD,并将第一列中的唯一条目(如A )和第二列的唯一条目(如B )放在列中,然后将A列放在值区域中,我发现所有匹配项和所有匹配项的计数。
这是一个笨重的方法,但是我注意到基于Python的方法已经提交了,我的回答基本上没有那么笨重!
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/67274644
复制相关文章
相似问题
腾讯云开发者
