
R中邻接值的查找
R中邻接值的查找
提问于 2021-04-08 11:37:24
这是我的数据集的一个例子。
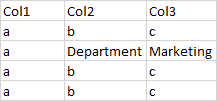
我正试着把部门的价值还给你。(在本例中为市场部)。另外的窍门是,我不知道哪一栏“部门”是存在的。(这个例子是Col2)。
我正在考虑的解决方案涉及以下几个方面
- 标识哪一列具有字符串"Department“。= colx
- 标识哪个列有值,根据步骤1. = coly
- 返回的coly值colx= "Department"
有人能给我指明正确的方向吗?
可重复数据
datt <-
structure(
list(
Col1 = c("a", "a", "a", "a"),
Col2 = c("b", "Department",
"b", "b"),
Col3 = c("c", "Marketing", "c", "c")
),
class = c("spec_tbl_df",
"tbl_df", "tbl", "data.frame"),
row.names = c(NA,-4L),
spec = structure(list(
cols = list(
Col1 = structure(list(), class = c("collector_character",
"collector")),
Col2 = structure(list(), class = c("collector_character",
"collector")),
Col3 = structure(list(), class = c("collector_character",
"collector"))
),
default = structure(list(), class = c("collector_guess",
"collector")),
skip = 1L
), class = "col_spec")
)Stack Overflow用户
发布于 2021-04-08 12:12:19
实现你描述的算法。循环遍历列名。查找包含"Department“的列,并将值存储为向量,以便稍后用于子集行。然后,查找其中包含“营销”的列,但前提是已经找到带有"Department“的列。一旦两者都被识别,就停止循环,然后将结果用于子集。
colx <- NULL
coly <- NULL
for ( x in names(datt) ) {
# Look for the column with "Department"
if ( any(grepl("Department", datt[[x]])) ) {
colx <- datt[[x]]
}
# Look for the column that has "Marketing"
if ( !is.null(colx) & any(grepl("Marketing", datt[[x]])) ) {
coly <- x
break
}
}
# Use the results to subset
datt[colx == "Department", coly]结果
[1] "Marketing"页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/67003200
复制相关文章
相似问题
腾讯云开发者
