
在SPSS中删除字符串中的非数字
考虑以下数据:
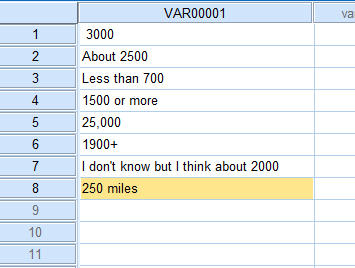
正如您所看到的,变量的值本质上是数字的,但在其中一些值中包含文本。我试过所有我能想到的do repeat...end repeat置换,尝试删除非数字值,只留下数字,但没有成功。
有什么语法能做到这一点吗?是否有一个函数来检查substr是否包含任何一组字符?然后,我可以创建一个表示所有数字的集合,循环遍历字符串中的每个字符,如果不在集合中,则用null替换它。
回答 1
Stack Overflow用户
发布于 2021-03-03 08:17:54
这个关于IBM支持的答案回答了一个有点类似的问题:https://www.ibm.com/support/pages/removing-unwanted-characters-strings
您将有更多的字符需要搜索(整个A,A,可能还有一些非字母字符),但它应该可以工作。如果您正在使用SPSS 223或更高版本,您还可能希望使用更新的、CHAR.INDEX和CHAR.REPLACE函数;请参阅关于它们的官方IBM SPSS文档:https://www.ibm.com/support/knowledgecenter/en/SSLVMB_23.0.0/spss/base/syn_transformation_expressions_string_functions.html。
稍后编辑(在OP:的澄清和建议之后)
在IBM示例中需要调整的是两件事:
- 在k次迭代后硬编码循环退出(而不是在#I=0时--在它找不到的第一个字符处停止)。在下面的示例中,k被设置为100.
- 指定要删除的所有字符:a到z、空格、引号(作为2个连续引号),等等;任何您认为需要清除的字符。然后,这应该会起作用(实际上,堆栈溢出、格式化目前似乎不能正常工作)。
计算x=LOWER(x)。
循环k=1到CHAR.LENGTH(x)。
计算#I = CHAR.INDEX(X,'abcdefghijklmnopqrstuvwxyz+,‘,1)。
如果#I >0 X=CONCAT( CHAR.SUBSTR(X,1,#I-1),CHAR.SUBSTR(X,#I+1))。
末端回路。
执行.
https://stackoverflow.com/questions/66449815
复制相似问题
腾讯云开发者
