
一维CNN、2D CNN和3D CNN输入形状的差异
我第一次为图像分类建立CNN模型,我有点搞不懂每种类型(一维CNN,2D CNN,3D CNN)的输入形状是什么,以及如何确定卷积层中的滤波器数目。我的数据是100x100x30,其中30是特性。以下是我在一维CNN中使用函数API Keras的文章:
def create_CNN1D_model(pool_type='max',conv_activation='relu'):
input_layer = (30,1)
conv_layer1 = Conv1D(filters=16, kernel_size=3, activation=conv_activation)(input_layer)
max_pooling_layer1 = MaxPooling1D(pool_size=2)(conv_layer1)
conv_layer2 = Conv1D(filters=32, kernel_size=3, activation=conv_activation)(max_pooling_layer1)
max_pooling_layer2 = MaxPooling1D(pool_size=2)(conv_layer2)
flatten_layer = Flatten()(max_pooling_layer2)
dense_layer = Dense(units=64, activation='relu')(flatten_layer)
output_layer = Dense(units=10, activation='softmax')(dense_layer)
CNN_model = Model(inputs=input_layer, outputs=output_layer)
return CNN_model
CNN1D = create_CNN1D_model()
CNN1D.compile(loss = 'categorical_crossentropy', optimizer = "adam",metrics = ['accuracy'])
Trace = CNN1D.fit(X, y, epochs=50, batch_size=100)然而,通过将Conv1D、Maxpooling1D更改为Conv2D和Maxpooling2D来尝试2D CNN模型时,我得到了以下错误:
ValueError: Input 0 of layer conv2d_1 is incompatible with the layer: : expected min_ndim=4, found ndim=3. Full shape received: (None, 30, 1),谁能告诉我,2D CNN和3D CNN的输入形状是什么?对输入数据的预处理可以做些什么呢?
回答 2
Stack Overflow用户
发布于 2021-02-16 09:49:14
TLDR;您的X_train可以看作是(批处理、空间dims.、通道)。内核并行地应用于所有通道的空间维度。所以二维CNN,需要两个空间维(batch, dim 1, dim 2, channels)。
因此,对于(100,100,3)形状的图像,你将需要一个2D CNN,它在所有三个频道上都有100米高和100宽的旋转。
让我们理解上面的陈述。
首先,你需要了解CNN (总体上)在做什么。
一个内核是在其特征映射/通道之间通过张量的空间维数进行转换,同时执行一个简单的矩阵操作(如点积)到相应的值。
内核在空间维度上移动
现在,假设您有100个图像(称为批处理)。每幅图像为28×28像素,有3个通道R,G,B(也称为CNN上下文中的特征映射)。如果我以张量的形式存储这些数据,形状将是(100,28,28,3)。
但是,我可以只拥有一个没有任何高度(可能像信号)的图像,或者,我可以有一个额外的空间维度的数据,比如视频(高度、宽度和时间)。
一般来说,基于CNN的神经网络的输入是这样的。

相同的内核,所有通道
您需要知道的第二个关键点是,2D内核将在两个空间维度上进行转换,但是相同的内核将在所有的功能映射/通道上完成这一任务。所以,如果我有一个(3,3)内核。这个相同的内核将被应用于R,G,B通道(并行),并在图像的Height和Width上移动。
操作是一个点积。
最后,操作(对于单个特征映射/通道和单个卷积窗口)可以可视化如下所示。
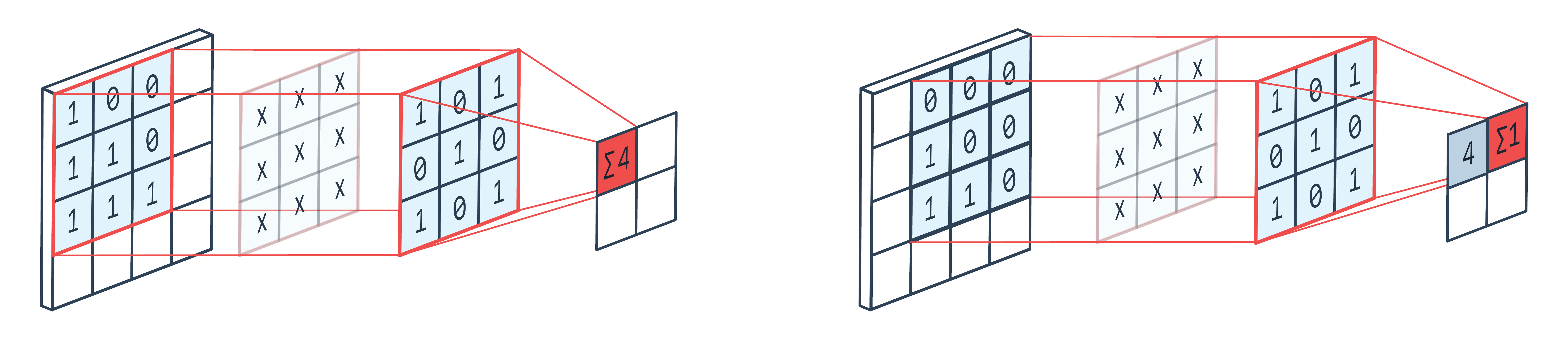
因此,,简而言之-
- A内核被应用于数据的空间维(
- )内核形状等于空间维的#
- A内核同时应用于所有的特征映射/通道
- 操作是内核和窗口
G 226之间的一个简单的点积
,让我们以具有单个功能映射/通道的张量为例(因此,对于图像,它将是灰度的)-
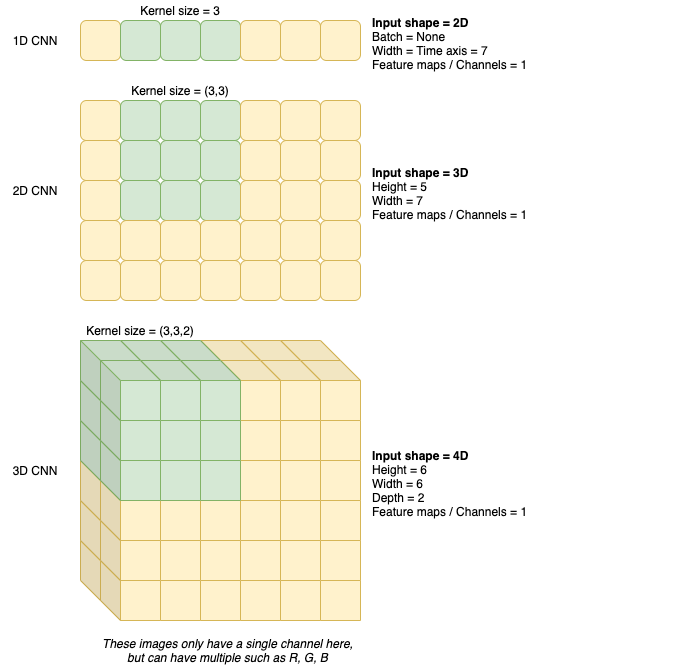
因此,有了这个直觉,我们可以看到,如果我想使用一个
1维,你的数据必须有一个空间维,这意味着每个样本都需要2D (空间维和通道),这意味着
X_train必须是一个三维张量(batch, spatial dimensions, channels)。
类似地,对于2D CNN,您将有2个空间维(例如H,W),并且是三维样本(H, W, Channels)和X_train将是(Samples, H, W, Channels)。
让我们用密码来试试-
import tensorflow as tf
from tensorflow.keras import layers
X_2D = tf.random.normal((100,7,3)) #Samples, width/time, channels (feature maps)
X_3D = tf.random.normal((100,5,7,3)) #Samples, height, width, channels (feature maps)
X_4D = tf.random.normal((100,6,6,2,3)) #Samples, height, width, time, channels (feature maps)为了申请一维CNN -
#With padding = same, the edge pixels are padded to not skip a few
#Out featuremaps = 10, kernel (3,)
cnn1d = layers.Conv1D(10, 3, padding='same')(X_2D)
print(X_2D.shape,'->',cnn1d.shape)
#(100, 7, 3) -> (100, 7, 10)为了申请2D CNN -
#Out featuremaps = 10, kernel (3,3)
cnn2d = layers.Conv2D(10, (3,3), padding='same')(X_3D)
print(X_3D.shape,'->',cnn2d.shape)
#(100, 5, 7, 3) -> (100, 5, 7, 10)对于3D CNN -
#Out featuremaps = 10, kernel (3,3)
cnn3d = layers.Conv3D(10, (3,3,2), padding='same')(X_4D)
print(X_4D.shape,'->',cnn3d.shape)
#(100, 6, 6, 2, 3) -> (100, 6, 6, 2, 10)Stack Overflow用户
发布于 2021-02-16 09:44:36
由100x100x30输入形状,您是说批次大小是100吗?还是每个数据的形状为100x100x30?在第二种情况下,您必须使用Conv2D层。每个层的输入形状应该是:
Conv1D:(size1,channel_number),Conv2D:(size1,size2,channel_number),Conv3D:(size1,size2,size3,channel_number)
1DCNN,2DCNN,3DCNN表示卷积层各核和信道的维数。
https://stackoverflow.com/questions/66220774
复制相似问题
腾讯云开发者
