
在ValueError中放置“`Replace = True`”:当“replace=False”时不能获取比总体更大的样本
在ValueError中放置“`Replace = True`”:当“replace=False”时不能获取比总体更大的样本
提问于 2021-02-14 22:34:36
试图复制一个Kaggle笔记本工作
我分割了一个数据集
# Split data
raw_train_df, valid_df = train_test_split(image_df, test_size = 0.25, random_state = 12345, stratify =
image_df['class_name'])
# Print results
print(raw_train_df.shape, 'Training data')
print(valid_df.shape, 'Validation data')
(11250, 10) Training data
(3750, 10) Validation data现在试着平衡一套训练:
fig, (ax1, ax2) = plt.subplots(1, 2, figsize = (20, 10))
raw_train_df.groupby('class_name').size().plot.bar(ax = ax1)
train_df = raw_train_df.groupby('class_name').\
apply(lambda x: x.sample(TRAIN_SAMPLES//15)).\ # Here I put 15 instead of 3, because I have 15
classes
reset_index(drop=True)
train_df.groupby('class_name').size().plot.bar(ax=ax2)
print(train_df.shape[0], 'new training size')我收到一个错误:
ValueError Traceback (most recent call last)
<ipython-input-16-3b4d2b82246c> in <module>()
1 fig, (ax1, ax2) = plt.subplots(1, 2, figsize = (20, 10))
2 raw_train_df.groupby('class_name').size().plot.bar(ax = ax1)
----> 3 train_df = raw_train_df.groupby('class_name'). apply(lambda x:
x.sample(TRAIN_SAMPLES//15)). reset_index(drop=True)
4 train_df.groupby('class_name').size().plot.bar(ax=ax2)
5 print(train_df.shape[0], 'new training size')
4 frames
/usr/local/lib/python3.6/dist-packages/pandas/core/generic.py in sample(self, n, frac, replace,
weights, random_state, axis)
4993 )
4994
-> 4995 locs = rs.choice(axis_length, size=n, replace=replace, p=weights)
4996 return self.take(locs, axis=axis)
4997
mtrand.pyx in numpy.random.mtrand.RandomState.choice()
ValueError: Cannot take a larger sample than population when 'replace=False'图像如下所示
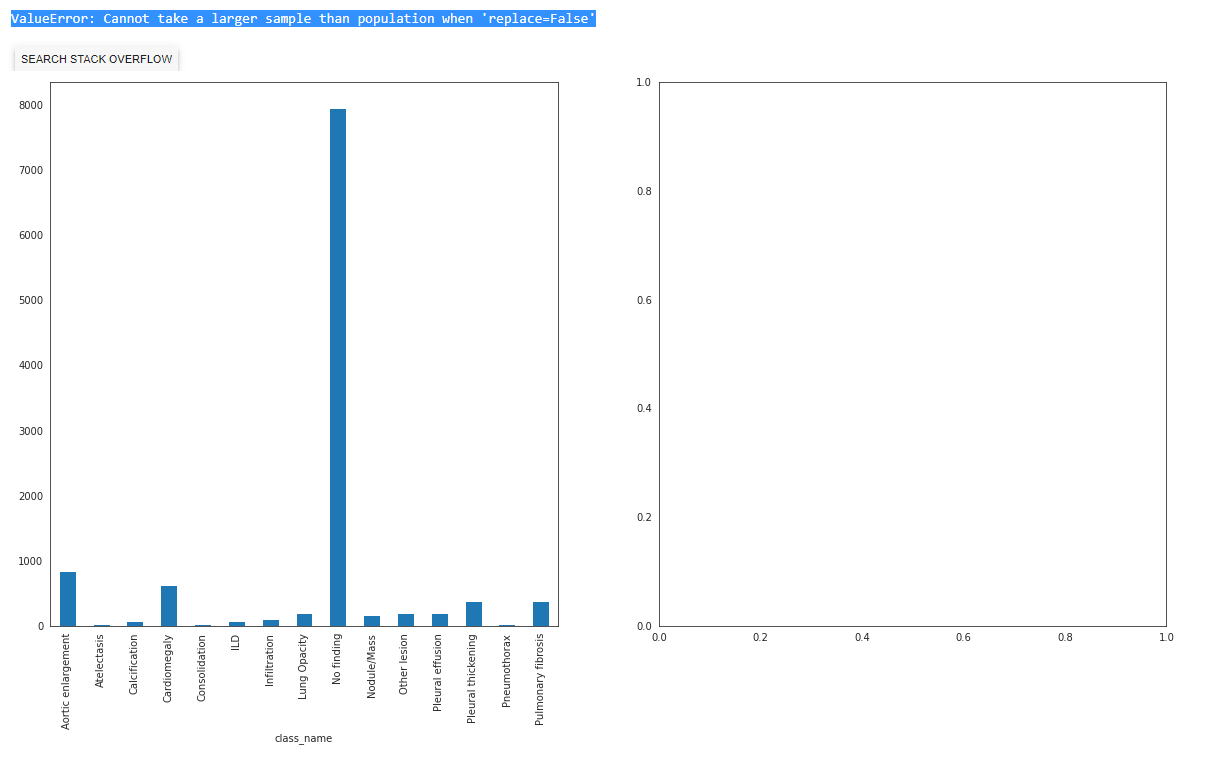
当您需要将Replace = True放在某个地方时,这是一个常见的错误,但我不知道确切的位置。
回答 1
Stack Overflow用户
回答已采纳
发布于 2021-02-15 04:44:26
错误在于在设置x.sample(TRAIN_SAMPLES//15)的行中调用train_df。
这可以根据以下几个方面进行追踪:
- 错误跟踪消息将错误指向将值赋值给
train_df的行(如箭头----> 3 train_df所示)。 - 除了x.sample()调用之外,此行中的所有熊猫函数调用都没有参数x.sample。也就是说,groupby()、apply()和reset_index()都没有参数
replace=True/False。
如果有必要,您可以参考Series.sample的熊猫API指南来获得更多的错误提示。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/66200784
复制相关文章
相似问题
腾讯云开发者
