
如何通过匹配两个DataFrames获得记录列表?
如何通过匹配两个DataFrames获得记录列表?
提问于 2021-01-16 10:09:54
我正在为一个项目开发PySpark脚本。
我有这样的输入数据:
+---+---------+
| id|direction|
+---+---------+
| 2| up|
| 3| up|
| 4| down|
| 5| up|
| 6| down|
| 7| down|
+---+---------+我处理过的数据是:
+----+---+---------+-----+
| day| id|direction|count|
+----+---+---------+-----+
|day1| 1| up| 10|
|day1| 2| up| 40|
|day1| 3| up| 42|
|day1| 4| down| 39|
|day1| 5| up| 55|
|day1| 6| down| 43|
|day1| 7| down| 41|
|day2| 1| down| 39|
|day2| 2| up| 44|
|day2| 3| up| 50|
|day2| 4| down| 43|
|day2| 5| down| 34|
|day2| 6| down| 30|
|day2| 7| up| 23|
|day3| 1| down| 20|
|day3| 2| up| 25|
|day3| 3| up| 33|
|day3| 4| up| 41|
|day3| 5| up| 55|
|day3| 6| down| 33|
|day3| 7| down| 23|
|day4| 1| up| 45|
|day4| 2| up| 56|
|day4| 3| up| 60|
|day4| 4| down| 49|
|day4| 5| up| 61|
|day4| 6| down| 53|
|day4| 7| down| 40|
|day5| 1| up| 20|
|day5| 2| up| 30|
|day5| 3| up| 37|
|day5| 4| down| 19|
|day5| 5| up| 25|
|day5| 6| down| 23|
|day5| 7| down| 18|
|day6| 1| up| 11|
|day6| 2| down| 9|
|day6| 3| down| 8|
|day6| 4| down| 6|
|day6| 5| up| 23|
|day6| 6| up| 29|
|day6| 7| up| 34|
+----+---+---------+-----+我想要绘制一个与我的输入数据记录相匹配的天数图。
就像这里一样,day1, day4, day5与输入数据匹配。因此,我的最后输出将是3个用x-axis as id和y-axis as count表示第1、4和5天的行图。
我使用了groupBy()和join()函数,但它不会给出确切的结果。我也不确定如何绘制数据结果。我必须先把它转换成类似于list的结构吗?
编辑:我创建了包含几行的临时数据文件:
df_input = spark.createDataFrame({
(2, 'up', ),
(3, 'up', ),
(4, 'down', ),
(5, 'up', ),
(6, 'down', ),
(7, 'down', )
}, ['id', 'direction'])
df_input.sort('id').show()
df_proccsed_table = spark.createDataFrame({
('day1', 1, 'up', 10, ),
('day1', 2, 'up', 40, ),
('day1', 3, 'up', 42, ),
('day1', 4, 'down', 39, ),
('day1', 5, 'up', 55, ),
('day1', 6, 'down', 43, ),
('day1', 7, 'down', 41, ),
('day2', 1, 'down', 39, ),
('day2', 2, 'up', 44),
('day2', 3, 'up', 50),
('day2', 4, 'down', 43),
('day2', 5, 'down', 34),
('day2', 6, 'down', 30),
('day2', 7, 'up', 23),
('day3', 1, 'down', 20),
('day3', 2, 'up', 25),
('day3', 3, 'up', 33),
('day3', 4, 'up', 41),
('day3', 5, 'up', 55),
('day3', 6, 'down', 33),
('day3', 7, 'down', 23),
('day4', 1, 'up', 45),
('day4', 2, 'up', 56),
('day4', 3, 'up', 60),
('day4', 4, 'down', 49),
('day4', 5, 'up', 61),
('day4', 6, 'down', 53),
('day4', 7, 'down', 40),
('day5', 1, 'up', 20),
('day5', 2, 'up', 30),
('day5', 3, 'up', 37),
('day5', 4, 'down', 19),
('day5', 5, 'up', 25),
('day5', 6, 'down', 23),
('day5', 7, 'down', 18),
('day6', 1, 'up', 11),
('day6', 2, 'down', 9),
('day6', 3, 'down', 8),
('day6', 4, 'down', 6),
('day6', 5, 'up', 23),
('day6', 6, 'up', 29),
('day6', 7, 'up', 34),
}, ['day', 'id', 'direction', 'count'])
df_proccsed_table.sort('day', 'id').show(100)回答 1
Stack Overflow用户
回答已采纳
发布于 2021-01-16 10:52:47
您可以做一个左联接,并将每组id中的非空行数与df_input中的行数进行比较,以确定模式是否完全匹配。
import pyspark.sql.functions as F
filtered = df_proccsed_table.join(
df_input.toDF('id2', 'direction2'),
F.expr('id = id2 and direction = direction2'),
'left'
).withColumn(
'match',
F.expr(f'count(id2) over(partition by day) = {df_input.count()}')
).filter('match').drop('match', 'id2', 'direction2').sort('day', 'id')
filtered.show(999)
+----+---+---------+-----+
| day| id|direction|count|
+----+---+---------+-----+
|day1| 1| up| 10|
|day1| 2| up| 40|
|day1| 3| up| 42|
|day1| 4| down| 39|
|day1| 5| up| 55|
|day1| 6| down| 43|
|day1| 7| down| 41|
|day4| 1| up| 45|
|day4| 2| up| 56|
|day4| 3| up| 60|
|day4| 4| down| 49|
|day4| 5| up| 61|
|day4| 6| down| 53|
|day4| 7| down| 40|
|day5| 1| up| 20|
|day5| 2| up| 30|
|day5| 3| up| 37|
|day5| 4| down| 19|
|day5| 5| up| 25|
|day5| 6| down| 23|
|day5| 7| down| 18|
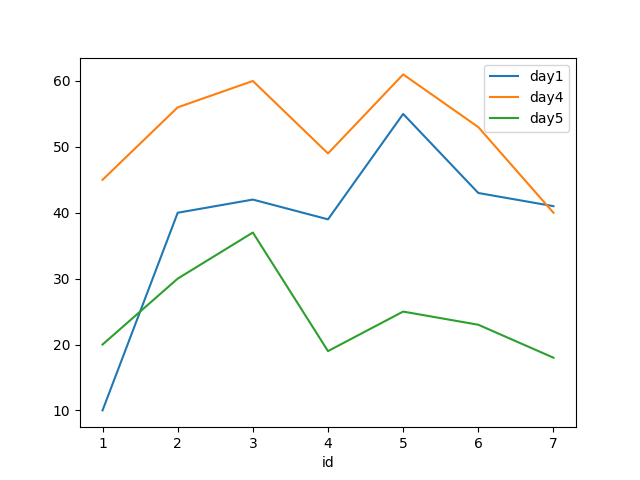
+----+---+---------+-----+要绘制结果:
pdf = filtered.toPandas()
pdf.set_index('id').groupby('day')['count'].plot(legend=True)
import matplotlib.pyplot as plt
plt.show()
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/65748453
复制相关文章
相似问题
腾讯云开发者
