
面具-RCNN控制面具召回的哪些参数?
我对微调蒙克-RCNN模型感兴趣,例如我正在使用的分割。目前,我已经训练了6个时代的模型和各种面具-RCNN损失如下:
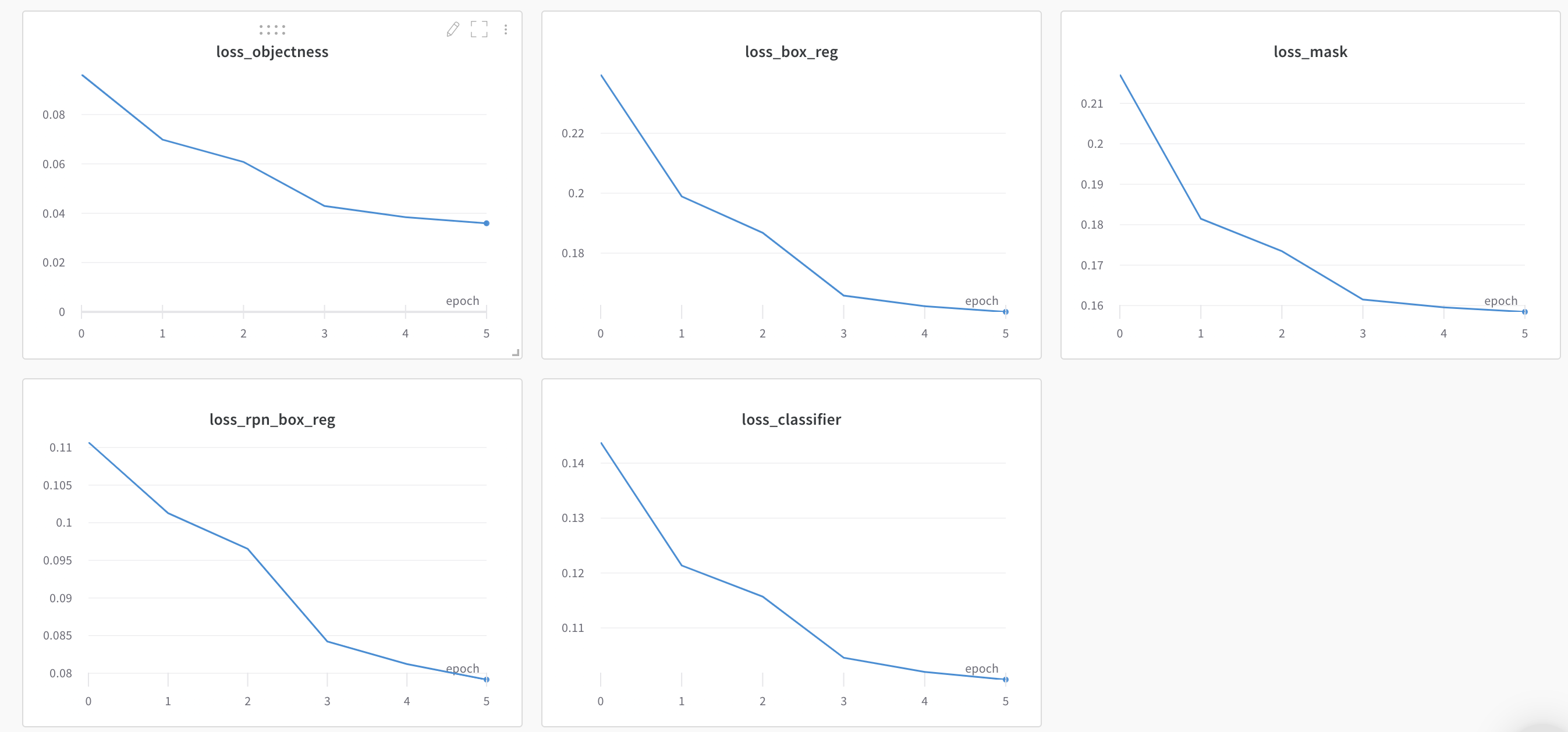
我之所以停下来,是因为COCO评估指标似乎在上一个时代有所下降:
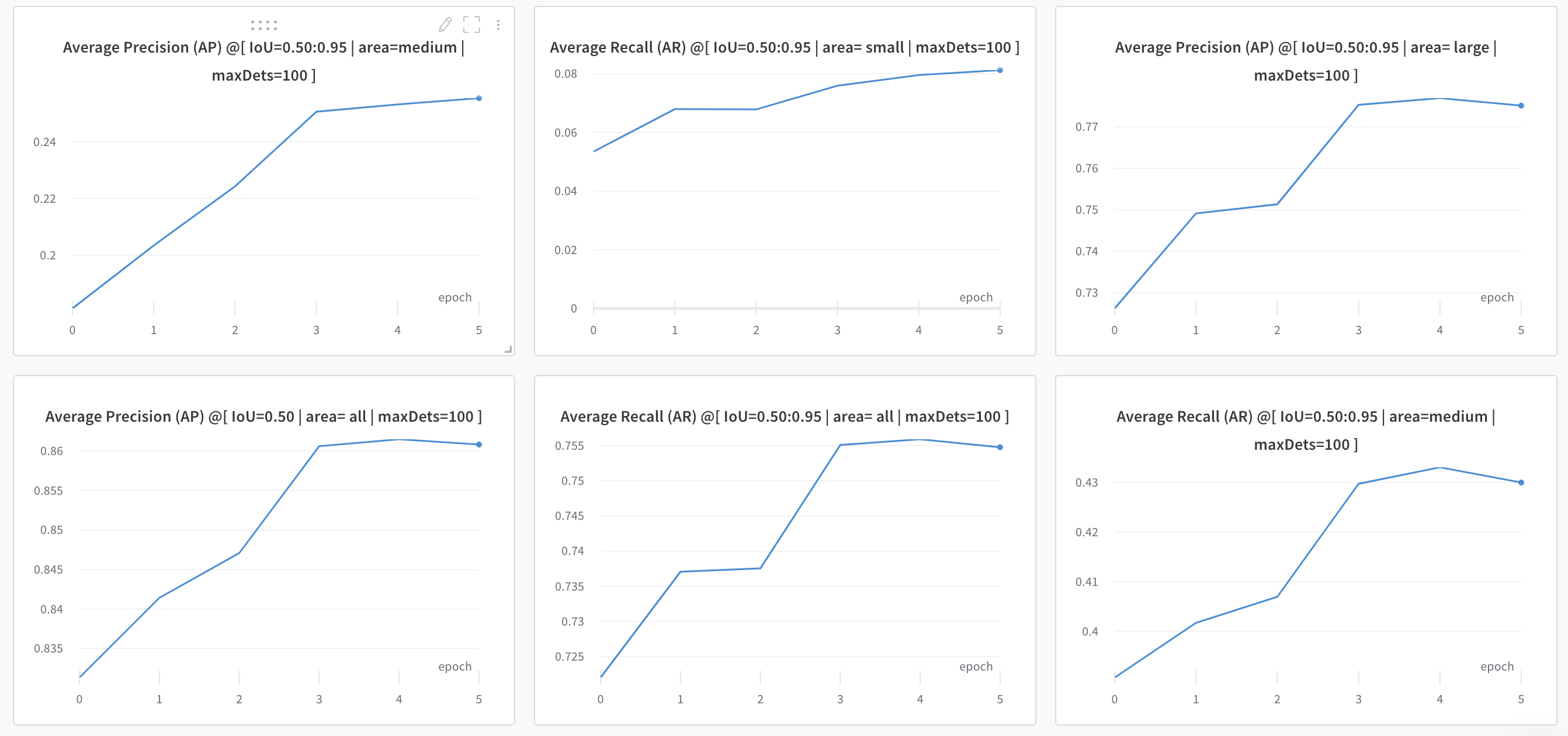
我知道这是一个很有意义的问题,但是我想获得一些关于如何理解哪些参数对改进评估指标最有影响的直觉。据我所知,有三个地方值得考虑:
- 应该查看批处理大小、学习速度和动量,这是使用学习速率为1e-4和批大小为2的SGD优化器吗?
- 应该考虑使用更多的培训数据或添加增强(我目前没有使用),我的数据集是当前相当大的40K图像?
- 应该查看特定的MaskRCNN参数吗?
我想,我很可能会被要求更具体地说明我想要改进什么,所以让我说,我想改善个人面具的召回。该模型运行良好,但并不完全捕捉到我想要的全部扩展。我还遗漏了具体学习问题的细节,因为我想获得如何处理这个问题的直觉。
回答 1
Stack Overflow用户
发布于 2021-01-15 07:41:17
几个注意事项:
- 6纪元是一种对网络来说太少的方式,即使您使用的是预先训练过的网络,也无法收敛。尤其是像resnet50这样的大公司。我想你至少需要50个时代。在一个经过预先训练的resnet18上,我开始在30年代后获得好的结果,resnet34需要+10-20个历元,而你的resnet50 + 40k的火车组图像肯定需要比6个更多的时间;
- 肯定使用了一个预先训练过的网络;
- ,在我的经验中,我没有得到我喜欢的SGD的结果。我开始使用AdamW + ReduceLROnPlateau调度器。网络的收敛速度相当快,就像50-60%的AP在7-8期,但在50-60个时代之后,只有在LR足够小的情况下,网络才会有很小的改进。你必须熟悉梯度下降的概念。我过去认为它就像你有更多的增强,你的“小山”是被“巨石”,你必须能够绕过,这是可能的,只有当你控制的LR。此外,AdamW还可以帮助解决过度适应问题.
我就是这样做的。对于具有较高输入分辨率的网络(您的输入图像是根据网络本身的输入进行缩放的),我使用更高的lr。
init_lr = 0.00005
weight_decay = init_lr * 100
optimizer = torch.optim.AdamW(params, lr=init_lr, weight_decay=weight_decay)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, verbose=True, patience=3, factor=0.75)
for epoch in range(epochs):
# train for one epoch, printing every 10 iterations
metric_logger = train_one_epoch(model, optimizer, train_loader, scaler, device,
epoch, print_freq=10)
scheduler.step(metric_logger.loss.global_avg)
optimizer.param_groups[0]["weight_decay"] = optimizer.param_groups[0]["lr"] * 100
# scheduler.step()
# evaluate on the test dataset
evaluate(model, test_loader, device=device)
print("[INFO] serializing model to '{}' ...".format(args["model"]))
save_and_print_size_of_model(model, args["model"], script=False)找到这样一个lr和重量衰减,使训练耗尽lr到一个非常小的值,就像你的初始lr的1/10,在训练结束。如果您有一个平台太频繁,调度程序很快就会把它带到非常小的值,网络将不会了解所有其他时代。
你的情节表明你的LR在训练的某个点过高,网络停止训练,然后AP下降。你需要不断的改进,即使是小的改进。网络训练的越多,它学到的关于你的领域的细节就越微妙,学习的速度也就越小。Imho,常数LR将不允许正确地这样做。
- 锚点生成器设置。下面是我初始化网络的方法。
def get_maskrcnn_resnet_model(名称,num_classes,预训练,res='normal'):打印(‘使用maskrcnn与{}主干.’.格式(名称))主干=resnet_fpn_backbone(名称,pretrained=pretrained,trainable_layers=5)大小= ((4,),(8,),(16,),(32,),(64,) aspect_ratios =(0.25,0.5,1.0,2.0,( torchvision.ops.MultiScaleRoIAlign(featmap_names='0','1','2','3',output_size=7,sampling_ratio=2) default_min_size = 800 default_max_size = 1333如果res == 'low':min_size = int(default_min_size / 1.25) max_size = int(default_max_size / 1.25) elif res ==‘normal’min_size = default_min_size max_size = default_max_size elif res== 'high':min_size = int(default_min_size * 1.25) max_size = int(default_max_size * 1.25) max_size=int(default_max_size*1.25)min_size=min_size,max_size=max_size,num_classes=num_classes,rpn_anchor_generator=anchor_generator,box_roi_pool=roi_pooler) model.roi_heads.detections_per_img = 512返回模型
我需要在这里找到一些小物体,为什么我要使用这样的锚点。
- 类的平衡问题.如果你只有你的目标和bg -没问题。如果您有更多的课程,那么请确保您的培训分割(训练的80%和测试的20% )或多或少地精确地应用于您特定培训中使用的所有类。
祝好运!
https://stackoverflow.com/questions/65694335
复制相似问题
腾讯云开发者
