
将多索引数据的索引值提取为python中的简单列表。
将多索引数据的索引值提取为python中的简单列表。
提问于 2021-01-11 03:08:29
我从熊猫数据中提取了索引值,并希望将它们作为列添加到新的dataframe中。但是python抛出一个错误,指示提取的索引具有作为提取数据的结构(行x列)。
如何将dataframe的索引值提取为可用作普通列表的简单列表?
错误:
ValueError: Shape of passed values is (10, 1), indices imply (10, 10)我试过的是:
## 1
pd.DataFrame(subset_df.index, subset_df[var], percentiles, percentiles_main)
## 2
ix = subset_df.index.get_level_values('College').tolist()
pd.DataFrame(ix, subset_df[var], percentiles, percentiles_main)
## 3
ix = [i for i in subset_df.index.get_level_values('College')]
pd.DataFrame(ix, subset_df[var], percentiles, percentiles_main)
## 4
ix = [i for i in subset_df.index.get_level_values('College').values]
## 5
ix = [i for i in subset_df.index.get_level_values('College').values.tolist()]
## 6
ix = subset_df.index.get_level_values('College').to_numpy()
## 7
ix = [i for i in subset_df.index.get_level_values('College').array]
## 8
pd.DataFrame(pd.IndexSlice[ix], percentiles, percentiles_main)
## 9
import operator
index = subset_df.index.tolist()
desired_index = list(set(map(operator.itemgetter(1), index)))
pd.DataFrame(desired_index, ptiles, ptiles_main)上述所有方法都提供了相同的ValueError。
要重新创建该问题:
import numpy as np
import pandas as pd
# Import data
url = "https://statlearning.com/College.csv"
dfo = pd.read_csv(url)
dfo.head(1)
# Add college names as 2nd index
df = dfo.set_index('Unnamed: 0', append=True)
df.rename_axis(index=['SN', 'College'], inplace=True)
# Created a subset of dataframe
subset_df = df.sort_values(by='Top10perc', axis=0, ascending=False)[0:10]
subset_df
# Calculation of percentiles
from scipy.stats import percentileofscore as prtl
ptiles_main = [round(prtl(df['Top10perc'],i,'weak'),2) for i in subset_df['Top10perc']]
ptiles = [round(prtl(df['Grad.Rate'],i,'weak'),2) for i in subset_df['Grad.Rate']]
# Creating a new dataframe with college names and percentiles
## this is where I'm getting ValueError
pd.DataFrame(subset_df.index.get_level_values('College').values.tolist(), ptiles, ptiles_main)
#> ValueError: Shape of passed values is (10, 1), indices imply (10, 10)
# this is the output without trying to add index
pd.DataFrame(ptiles, ptiles_main)
# 0
# 100.00 94.98
# 99.87 76.06
# 99.87 99.87
# 99.87 98.58
# 99.49 97.30
# 99.49 98.58
# 99.49 99.87
# 99.10 61.39
# 98.97 97.94
# 98.97 97.30期望产出:
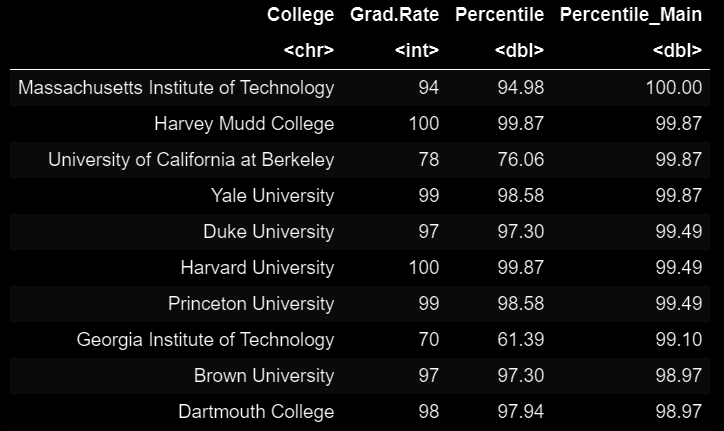
我的问题有两部分:
(更重要的部分)
1)如何将数据的索引值提取为简单列表,这些列表可以以任何方式使用--普通列表可以使用
(第二部分)
2)如何将大学名称添加到ptile_df中
Stack Overflow用户
发布于 2021-01-11 04:07:26
如果数据集类似于:
arrays = [np.array(["bar", "bar", "baz", "baz", "foo", "foo", "qux", "qux"]),
np.array(["one", "two", "one", "two", "one", "two", "one", "two"])]
df = pd.Series(np.random.randn(8), index=arrays)
bar one 1.421473
two 0.298886
baz one 1.538157
two -0.229495
foo one 2.686094
two 1.177376
qux one 1.550625
two -0.142154如果要将第一个索引作为列表,可以执行以下操作:
import operator
index = df.index.tolist()
print(index)
[('bar', 'one'), ('bar', 'two'), ('baz', 'one'), ('baz', 'two'), ('foo', 'one'), ('foo', 'two'), ('qux', 'one'), ('qux', 'two')]
desired_index = list(set(map(operator.itemgetter(0), index)))
print(desired_index)
['qux', 'baz', 'foo', 'bar']页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/65660884
复制相关文章
相似问题
腾讯云开发者
