
在notepad++中查找重复单词
在notepad++中查找重复单词
提问于 2020-12-15 19:07:11
我有一个具有文件层次结构的文件及其相应的CRC32代码:
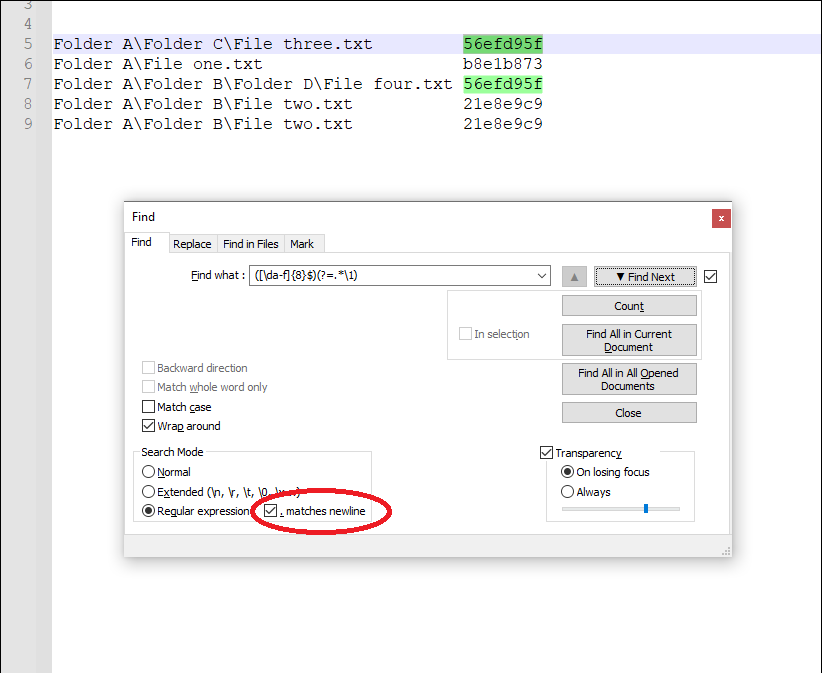
Folder A\Folder C\File three.txt 56efd95f
Folder A\File one.txt b8e1b873
Folder A\Folder B\Folder D\File four.txt 56efd95f
Folder A\Folder B\File two.txt 21e8e9c9我使用的是notepad++,我需要知道一个正则表达式,它能够使用相同的CRC32查找行。在本例中,我希望找到第1行和第3行。
我知道,使用\s[a-zA-Z0-9]{8,8}$,我可以匹配CRC32,但是如何检查这些匹配是否重复?
此外,如果我希望删除除CRC32之外的所有内容,为什么不使用表达式.*(?!\s[a-zA-Z0-9]{8,8}$)来用空字符串替换匹配并获得一个清晰的CRC32列表?
回答 2
Stack Overflow用户
回答已采纳
发布于 2020-12-15 20:12:15
您可以使用以下内容:
/([\da-f]{8}$)(?=.*\1)/gms([\da-f]{8}$)-查找一个CRC代码(?=.*\1)-确保CRC代码再次出现
https://regex101.com/r/fpIOCN/1
在Notepad++中,只需确保启用". matches换行符“
Stack Overflow用户
发布于 2020-12-15 23:13:53
找出被欺骗的重复:
(?s)\h([a-zA-Z0-9]{8})$(?=.*\h\1$)见证明。
要删除除CRC32代码以外的所有代码:
.*\h([a-zA-Z0-9]{8})$用$1代替。见另一种证明。然后,编辑->行操作->排序行,并在此之后删除连续的重复行。
解释
--------------------------------------------------------------------------------
\h horizontal whitespace
--------------------------------------------------------------------------------
( group and capture to \1:
--------------------------------------------------------------------------------
[a-zA-Z0-9]{8} any character of: 'a' to 'z', 'A' to
'Z', '0' to '9' (8 times)
--------------------------------------------------------------------------------
) end of \1
--------------------------------------------------------------------------------
$ end of a line
--------------------------------------------------------------------------------
(?= look ahead to see if there is:
--------------------------------------------------------------------------------
.* any character except \n (0 or more times
(matching the most amount possible))
--------------------------------------------------------------------------------
\h horizontal whitespace
--------------------------------------------------------------------------------
\1 what was matched by capture \1
--------------------------------------------------------------------------------
$ end of a line
--------------------------------------------------------------------------------
) end of look-ahead页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/65312187
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号