
从特定行读取CSV
从特定行读取CSV
提问于 2020-11-27 12:52:28
我正在编写一个处理气象站数据的程序,这是我从我的气象站得到的CSV:
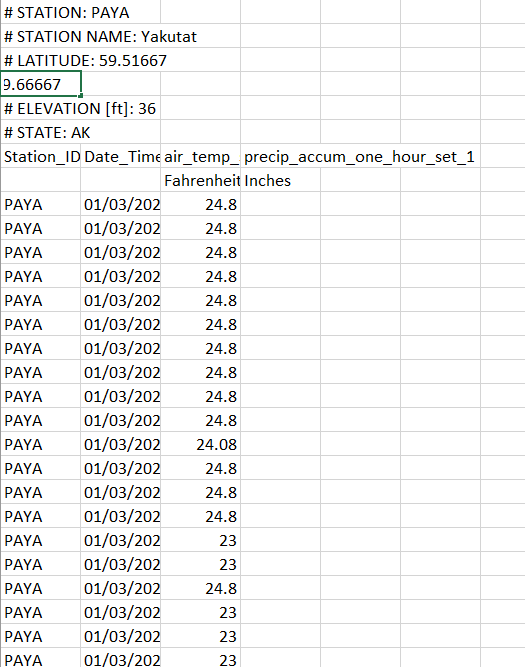
问题是熊猫很难打开它。首先,我收到了一条错误消息,我试图通过编写来绕过它:
test = pd.read_csv("PAYA(3).csv",error_bad_lines=False,skiprows = [0,7])另一个问题是,熊猫文件只显示前4行:
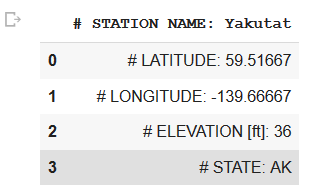
我怎么才能正确地读取文件呢?我想要的是把它分成四列,有日期,时间,降水,温度。我的最终目标是自动下载给定日期窗口的数据,并将变量堆叠到一个巨大的数组中。
回答 2
Stack Overflow用户
回答已采纳
发布于 2020-11-27 12:59:42
当skiprows参数传递给pandas.read_csv时,根据文档,您要求它跳过列表中的行,而不是行范围。
如果您想跳过前面的8行,只需传递skiprows=8。
更新:我发现以下内容对此数据集最有效:
>>> pd.read_csv(url, header=6, skiprows=[7])这将使用行6作为列名,跳过行7,这将给出一些单元。使用header=6隐式跳过行7作为数据的开始。
结果:
Station_ID Date_Time air_temp_set_1 precip_accum_one_hour_set_1
0 PAYA 01/03/2020 22:00 AKST 24.80 NaN
1 PAYA 01/03/2020 22:05 AKST 24.80 NaN
2 PAYA 01/03/2020 22:10 AKST 24.80 NaN
3 PAYA 01/03/2020 22:15 AKST 24.80 NaN
4 PAYA 01/03/2020 22:20 AKST 24.80 NaN
.. ... ... ... ...
287 PAYA 01/04/2020 21:45 AKST 8.60 NaN
288 PAYA 01/04/2020 21:50 AKST 8.60 NaN
289 PAYA 01/04/2020 21:53 AKST 10.04 NaN
290 PAYA 01/04/2020 21:55 AKST 8.60 NaN
291 PAYA 01/04/2020 22:00 AKST 8.60 NaNStack Overflow用户
发布于 2020-11-27 13:05:03
您可能希望将参数skiprows更改为:
test = pd.read_csv("PAYA.csv", skiprows=range(0,7), sep=',', error_bad_lines=False)页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/65037704
复制相关文章
相似问题
腾讯云开发者
