
如何根据R中多个其他列的NAs和零创建新列?
如何根据R中多个其他列的NAs和零创建新列?
提问于 2020-10-23 09:20:49
我有一个数据集,可以追踪数以百万计的公司多年来的收入。这些数据看起来像下面的简化版本:
dat <- data.frame(Company = c("a","b","c","d","e","f"), rev_2001 = c(NA, 20, 10, NA, NA, 10),
rev_2002 = c(10, 50, 20, 30, NA, 0), rev_2003 = c(20, NA, 0, NA, NA, 30), rev_2004 = c(NA, 60, 0, 50, NA, 50), rev_2005 = c(NA, 30, NA, 0, NA, 60))我想要创建一个变量(一个我们可以标记为“closure.year”的新列),它将捕捉到该公司去年的收入与0或NA不同。我在为两件事而挣扎:
- ,我想忽略0和NAs,但我不想把NAs转换成零,也不想反过来;
- ,正如你所看到的,数据有一些零和NAs,不仅在过去几年中观察到,而且在一些中间年份。如果该公司在一年后的收入为0或NA,那一年将不被视为closure.year。此外,如果该公司没有停止获得收入,变量closure.year将是NA.
。
总之,我想要的最后数据如下:
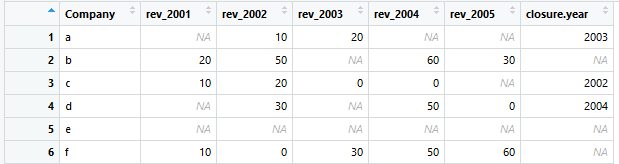
非常感谢!
回答 2
Stack Overflow用户
发布于 2020-10-23 10:45:57
您可以尝试下面的代码
z <- do.call(cbind,Reduce(`|`,rev(replace(dat,is.na(dat),0)[-1]),accumulate = TRUE))
x <- max.col(z>0,"first")
dat$closure.year <- as.numeric(gsub(".*_","",names(dat[-1])[ncol(dat)-replace(x,x == 1,NA)]))这给
> dat
Company rev_2001 rev_2002 rev_2003 rev_2004 rev_2005 closure.year
1 a NA 10 20 NA NA 2003
2 b 20 50 NA 60 30 NA
3 c 10 20 0 0 NA 2002
4 d NA 30 NA 50 0 2004
5 e NA NA NA NA NA NA
6 f 10 0 30 50 60 NAStack Overflow用户
发布于 2020-10-23 09:47:36
从宽格式转换为长格式如何?
df_long <- gather(df,year,value,rev_2001:rev_2005,factor_key=TRUE)
df_long %>% group_by(Company) %>% top_n(1, value)您需要添加一些更多的逻辑来处理0和NA条件,但是这种方法可能会有所帮助。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/64497324
复制相关文章
相似问题
腾讯云开发者
