
YouTube的自动字幕比产生了更好的效果(模型:视频,UseEnhanced: true)。这怎么可能?
这里我的谷歌语音设置给AI发短信
以下是语音到文本AI:https://justpaste.it/speechtotext2的输出文件
以下是YouTube自动标题的输出文件:https://justpaste.it/ytautotranslate
这是视频链接:channel=SoftwareEngineeringCourses SECourse
这是提供给Google:1.flac的视频的音频文件。
这里我提供分配给SRT文件的时间。
YouTube的SRT:https://drive.google.com/file/d/1yPA1m0hPr9VF7oD7jv5KF7n1QnV3Z82d/view?usp=sharing
Google to Text的SRT (由YouTube分配的时间):https://drive.google.com/file/d/1AGzkrxMEQJspYenCbohUM4iuXN7H89wH/view?usp=sharing
我比较了一些句子,当然YouTube的自动翻译更好
例如
Google文字演讲: Represent the **doctor** representation is one of the hardest part of computer AI you will learn about more about that in the future lessons.
What does this mean? Do you think this means that we are not just focused on behavior and **into doubt**. It is more about the reasoning when a human takes an action. There is a reasoning behind it.YouTube的自动字幕: represent the **data** representation is one of the hardest part of computer ai you will we will learn more about that in the future lessons
what does this mean do you think this means that we are not just focused on behavior and **input** it is more about the reasoning when a human takes an action there is a reasoning behind it我查了很多案例,YouTube猜对了词要好得多。这怎么可能?
这是我用来提取视频音频的命令:ffmpeg -i "input.mkv" -af aformat=s16:48000:output.flac
回答 1
Stack Overflow用户
发布于 2020-10-13 22:54:25
Youtube自动字幕特征的自动字幕和语音到文本识别的转录都是通过机器学习算法产生的,在这种情况下,转录的质量可能会因不同的方面而不同。
需要注意的是,语音到文本API利用机器学习算法对其进行转录,这些算法随着时间的推移得到改进,其结果可能因输入文件和请求配置的不同而有所不同。帮助谷歌转录模型的一种方法是启用数据录井,这将使谷歌能够从您的音频转录请求中收集数据,这将有助于改进用于识别语音音频的机器学习模型,包括增强模型。
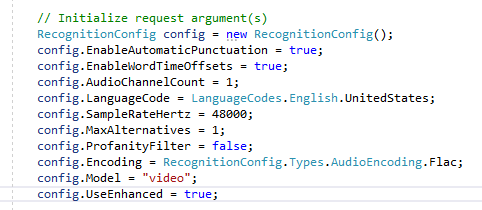
此外,在将语音请求配置为Text时,可以指定RecognitionConfig设置。该参数包含编码、sampleRateHertz、languageCode、maxAlternatives、profanityFilter和speechContext,每个参数对文件转录的准确性起着重要的作用。
特别是对于FLAC音频文件,无损压缩有助于提高所提供音频的质量,因为原始数字示例的质量没有下降,FLAC使用从0(最快)到8(最小文件大小)的压缩级别参数。
此外,语音到文本API提供了不同的方法来提高转录的准确性,例如:
- 语音自适应:此功能允许您指定STT应在音频数据中更频繁地识别的单词和/或短语
- 语音自适应增强:该功能允许您根据音频数据中应该识别的单词和/或短语的频率,向单词和/或短语添加数字权重。
- 短语提示:发送向语音识别任务提供提示的单词和短语列表
这些功能可以帮助您提高语音到文本API识别音频文件的准确性。
最后,请参考发言文本最佳做法,以改善您的音频文件的转录,这些建议是为了更高的效率和准确性以及合理的响应时间从API。
https://stackoverflow.com/questions/64322604
复制相似问题
腾讯云开发者
