
如何使用熊猫合并excel输出文件中具有相同内容的多个列
如何使用熊猫合并excel输出文件中具有相同内容的多个列
提问于 2020-09-13 21:45:30
我有一只像桌子下面的熊猫。对于第一列中的每个SITEID,对于其他列,如优先级、区域和供应商,我有相同的值,而在History列中则不相同。
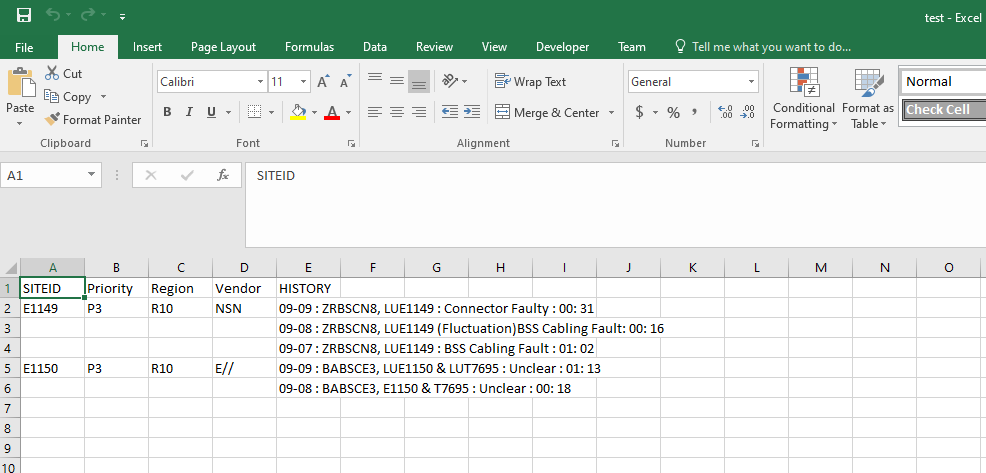
SITEID Priority Region Vendor HISTORY
====== ========= ====== ======= =================================================================
E1149 P3 R10 NSN 09-09 : ZRBSCN8, LUE1149 : Connector Faulty : 00: 31
=====================================================================================================
E1149 P3 R10 NSN 09-08 : ZRBSCN8, LUE1149 (Fluctuation)BSS Cabling Fault: 00: 16
=====================================================================================================
E1149 P3 R10 NSN 09-07 : ZRBSCN8, LUE1149 : BSS Cabling Fault : 01: 02
=====================================================================================================
E1150 P3 R10 E// 09-09 : BABSCE3, LUE1150 & LUT7695 : Unclear : 01: 13
=====================================================================================================
E1150 P3 R10 E// 09-08 : BABSCE3, E1150 & T7695 : Unclear : 00: 18
=====================================================================================================首先,我想将每个siteID的前四列(SITEID、优先级、区域和供应商)合并,然后将所有相关记录放在History列中,如下所示:
SITEID Priority Region Vendor HISTORY
====== ========= ====== ======= =================================================================
E1149 P3 R10 NSN 09-09 : ZRBSCN8, LUE1149 : Connector Faulty : 00: 31
09-08 : ZRBSCN8, LUE1149 (Fluctuation)BSS Cabling Fault:00: 16
09-07 : ZRBSCN8, LUE1149 : BSS Cabling Fault : 01: 02
=====================================================================================================
E1150 P3 R10 E// 09-09 : BABSCE3, LUE1150 & LUT7695 : Unclear : 01: 13
09-08 : BABSCE3, E1150 & T7695 : Unclear : 00: 18
=====================================================================================================在excel输出文件中使用xlswriter等最有效的方法是什么?我尝试了许多解决方案,如swaplevel,但没有结果。
回答 2
Stack Overflow用户
回答已采纳
发布于 2020-09-14 05:19:02
您可以使用带有分隔符的groupby和agg使用简单的.join和\n。
cols = ['SITEID', 'Priority', 'Region', 'Vendor']
df_merged = df.groupby(cols, as_index=False).agg('\n'.join)然后将此合并数据存储为excel,如下所示:
df_merged.to_excel('file.xlsx')结果:

Stack Overflow用户
发布于 2020-09-13 23:15:09
您可以简单地使用.loc查找相关列的重复行。loc有两个部分: 1.行和2列:
- For
rows,可以使用.duplicated()并通过传递subset=([])指定要查找重复项的列。这将为重复行返回True。== ''
- for
columns,可以将要更改的值的列传递为空格,并将这些指定的rows和columns设置为空白。
df.loc[df.duplicated(subset=(['SITEID','Priority','Region','Vendor'])),['SITEID','Priority','Region','Vendor']] = ''
df
Out[1]:
SITEID Priority Region Vendor \
0 E1149 P3 R10 NSN
1
2
3 E1150 P3 R10 E//
4
HISTORY
0 09-09 : ZRBSCN8, LUE1149 : Connector Faulty : ...
1 09-08 : ZRBSCN8, LUE1149 (Fluctuation)BSS Cabl...
2 09-07 : ZRBSCN8, LUE1149 : BSS Cabling Fault :...
3 09-09 : BABSCE3, LUE1150 & LUT7695 : Unclear :...
4 09-08 : BABSCE3, E1150 & T7695 : Unclear : 00: 18
df.to_csv('test.csv', index=False)
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/63875874
复制相关文章
相似问题
腾讯云开发者
