
有什么方法可以正确地将熊猫的两个时间序列合并成不同的dims?
有什么方法可以正确地将熊猫的两个时间序列合并成不同的dims?
提问于 2020-09-08 23:18:41
我打算加入熊猫的两个不同维度的时间序列。第一时间序列是关于covid19每日个案数据,第二时间序列是食品加工厂的每日削减统计,然后我想加入合并的数据与另一个数据通过它的公共列。首先,我想加入他们的日期与特定的规格。在切分时间序列中,数据是按县级记录的,而在日裁剪时间序列中,可以是各县的平均日割时间序列,也可以是均匀分布的日割时间序列。为了使加入这两个时间序列更符合逻辑,我进行了一些聚合并尝试加入,但它并不像我所期望的那样工作。有人能提出在熊猫身上实现这一目标的可能方法吗?有什么想法吗?
当前的尝试&可复制的数据
这里是gist中的时间序列数据来自纽约时报covid19数据和每日切割时间序列来自食品加工机构。以下是我目前的尝试:
import pandas as pd
df1= pd.read_csv("us_covid_by_counties.csv")
df1 = df1.drop(columns=['Unnamed: 0'], inplace=True)
df2= pd.read_csv("daily_cut.csv")
df2 = df2.drop(columns=['Unnamed: 0'], inplace=True)
## process and aggregate covid time series
ctyList = list(df1['county'].unique())
df1_new= {}
for c in ctyList:
cty_df = df1[df1['county']==c]
cty_df['new_cases'] = cty_df['cases'].diff()
cty_df['new_deaths'] = cty_df['deaths'].diff()
df1_new[c] = cty_df
df1_new = pd.DataFrame.from_dict(df1_new, orient='index')然后,我试着用这样的方式将它们合并:
df_merged = pd.concat([df1_new , df2]).sort_values('date').reset_index(drop=True)更新
如果可以正确地将df1_new和df2合并,我想再次加入df_merged和这些数据 by county_state。有什么办法能在熊猫身上做到这一点吗?
但我很难正确地加入这两个时间序列。有人能提出任何可能的想法来使这件事成功吗?有什么想法吗?
回答 2
Stack Overflow用户
回答已采纳
发布于 2020-09-09 16:09:24
在你最初的问题中,你提到了两个数据。在你的评论中,你提到了另一个数据。这是另一个问题吗?merge_asof适用于原始数据集。请见下文
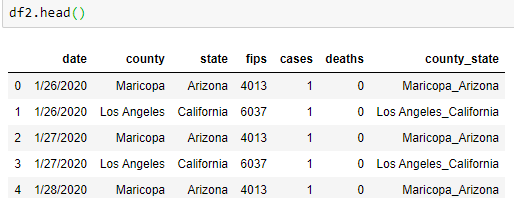
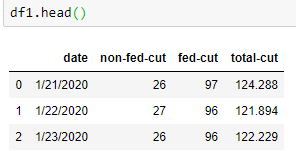
这是将数据类型更改为日期时间。
df1['date'] = pd.to_datetime(df1['date'])
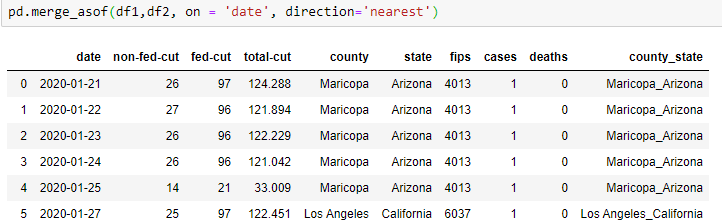
df2['date'] = pd.to_datetime(df2['date'])这是我得到的输出
Stack Overflow用户
发布于 2020-09-09 00:37:34
在评论中完成@XXavier的建议:
确保正确导入日期:
df1 = pd.read_csv('data/us_covid_by_counties.csv', parse_dates=['date']).drop(columns=['Unnamed: 0'])
df2 = pd.read_csv('data/daily_cut.csv', parse_dates=['date']).drop(columns=['Unnamed: 0'])添加您想要的列:
df1['new_cases'] = df1.groupby(['county'])['cases'].diff()
df1['new_deaths'] = df1.groupby(['county'])['deaths'].diff()创建合并的df:
df_merged = pd.merge_asof(df1, df2, on="date", direction='nearest')页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/63802754
复制相关文章
相似问题
腾讯云开发者
