
如何将Pandas DataFrame导出到CSV文件
如何将Pandas DataFrame导出到CSV文件
提问于 2020-08-13 17:16:52
如何将Pandas DataFrame导出到CSV文件并从下面的字符串读取?
series: [{
name: 'Water',
data: [[90, 50000],[91, 53000],[92, 56000],[93, 62000],[94, 68000],[95, 76000],[96, 83000],[97, 91000],[98, 98000],[99, 105000],[100, 110000],[101, 114000],[102, 116000],[103, 116000],[104, 114000],[105, 111000],[106, 105000],[107, 99000],[108, 92000],[109, 84000],[110, 77000],[111, 69000],[112, 62000],[113, 56000],[114, 52000],[115, 48000],[116, 46000],[117, 45000],[118, 46000],[119, 47000],[120, 48000],[121, 50000],[122, 52000],[123, 54000],[124, 55000],[125, 54000],[126, 53000],[127, 51000],[128, 47000],[129, 43000],[130, 38000]]
},{
name: 'tea',
data: [[90, 47000],[91, 53000],[92, 57000],[93, 59000],[94, 59000],[95, 58000],[96, 55000],[97, 53000],[98, 51000],[99, 51000],[100, 53000],[101, 58000],[102, 64000],[103, 72000],[104, 80000],[105, 89000],[106, 97000],[107, 102000],[108, 105000],[109, 105000],[110, 101000],[111, 95000],[112, 87000],[113, 77000],[114, 67000],[115, 57000],[116, 50000],[117, 46000],[118, 45000],[119, 47000],[120, 53000],[121, 61000],[122, 70000],[123, 81000],[124, 90000],[125, 98000],[126, 103000],[127, 105000],[128, 104000],[129, 100000],[130, 94000]]
},{
name: 'Tonic',
data: [[90, 63000],[91, 68000],[92, 73000],[93, 78000],[94, 82000],[95, 85000],[96, 86000],[97, 86000],[98, 84000],[99, 81000],[100, 77000],[101, 71000],[102, 66000],[103, 60000],[104, 54000],[105, 50000],[106, 46000],[107, 44000],[108, 44000],[109, 46000],[110, 49000],[111, 54000],[112, 60000],[113, 67000],[114, 74000],[115, 81000],[116, 88000],[117, 94000],[118, 99000],[119, 102000],[120, 104000],[121, 104000],[122, 102000],[123, 99000],[124, 95000],[125, 91000],[126, 86000],[127, 81000],[128, 77000],[129, 74000],[130, 72000]]
}]这是我的密码:
newdata = eval(string)
df = pd.DataFrame(newdata)
df.to_csv('filename.csv', index=False)
print(df)这是to_csv调用所需的输出:
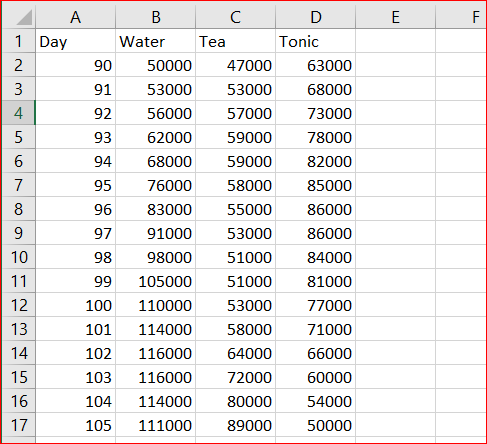
回答 1
Stack Overflow用户
回答已采纳
发布于 2020-08-13 17:29:44
假设series是字典或json对象。我们可以用I/O完成初始的pd.json_normalize,然后用pd.Crosstab重新构造数据格式。
df = pd.json_normalize(series,
record_path="series")\
.explode("data")\
.reset_index(drop=True)
df1 = (
df[["name"]]
.join(pd.DataFrame(df["data"].tolist()))
.rename(columns={0: "Day", 1: "Data"})
)
df2 = pd.crosstab(df1.Day,df1.name,df1.Data,aggfunc=lambda x : x)print(df2)
name Tonic Water tea
Day
90 63000 50000 47000
91 68000 53000 53000
92 73000 56000 57000
93 78000 62000 59000
94 82000 68000 59000
95 85000 76000 58000
96 86000 83000 55000
97 86000 91000 53000
98 84000 98000 51000
99 81000 105000 51000
100 77000 110000 53000
101 71000 114000 58000
102 66000 116000 64000
103 60000 116000 72000
104 54000 114000 80000
105 50000 111000 89000
106 46000 105000 97000
107 44000 99000 102000
108 44000 92000 105000
109 46000 84000 105000
110 49000 77000 101000
111 54000 69000 95000
112 60000 62000 87000
113 67000 56000 77000
114 74000 52000 67000
115 81000 48000 57000
116 88000 46000 50000
117 94000 45000 46000
118 99000 46000 45000
119 102000 47000 47000
120 104000 48000 53000
121 104000 50000 61000
122 102000 52000 70000
123 99000 54000 81000
124 95000 55000 90000
125 91000 54000 98000
126 86000 53000 103000
127 81000 51000 105000
128 77000 47000 104000
129 74000 43000 100000
130 72000 38000 94000页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/63400153
复制相关文章
相似问题
腾讯云开发者
