
熊猫数据的分裂分组观测
熊猫数据的分裂分组观测
提问于 2020-08-09 19:32:38
我的字典,mydict,包含了几个数据。每个数据包含不同数量的观察,但相同数量的特性。VARIABLEx既是字典中的键,也是数据帧中的第一个特性。VARIABLEx可以是数字字符,也可以是数字字符(varnum),并且可能存在“自然”排序/排序。
我的问题是上表中的VARIABLE1 (如果它不能显示我提供了下面的代码)。该变量包含诸如1、2、. 6之类的值,但也包含1-3和4-6;当PRODUCT1和PRODUCT3遵循第一个“语法”(1,2,3,…)时,VARIABLE1和…包含实际值。6)然而,当VARIABLE1 i遵循后者时,999 (NaN-值)。FOr,PRODUCT2,正好相反。
我想要的是:
麦迪特:
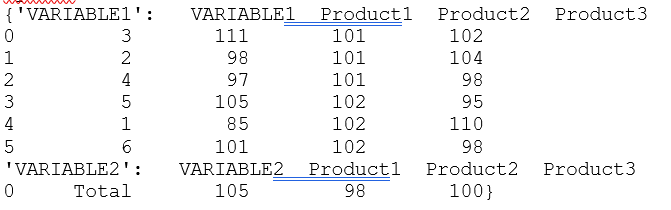
即PRODUCT2的“实值”代替相应的观测值“999”,并从数据中删除“分组值”(1-3和4-6)。
我的代码:
import pandas as pd
mydict = {}
dict1 = {'VARIABLE1': ['3', '2', '4', '5', '1', '6', '1--3', '4--6'],
'Product1': [111, 98, 97, 105, 85, 101, 999, 999] ,
'Product2': [999, 999, 999, 999, 999, 999, 101, 102] ,
'Product3': [102, 104, 98, 95, 110, 98, 999, 999]}
dict2 = {'VARIABLE2': ['Total'],
'Product1': [105],
'Product2': [98],
'Product3': [100]}
mydict['VARIABLE1'] = pd.DataFrame(dict1)
mydict['VARIABLE2'] = pd.DataFrame(dict2)
print('\n mydict: ')
mydict回答 1
Stack Overflow用户
回答已采纳
发布于 2020-08-10 09:34:27
一步一步地:首先定义我们正在处理的df:
df = pd.DataFrame(dict1)分离为2个数据文件:
dft = df[df.VARIABLE1.str.contains('--')]
df = df[~df.VARIABLE1.str.contains('--')]然后使用split将字符串转换为列表,然后使用lambda函数将字符串转换为范围,并使用expode方法创建新行。结果存储在df.Product2中
df.Product2 = dft.assign(VAR1=dft['VARIABLE1'].str.split('--')\
.map(lambda r: range(int(r[0]),int(r[1])+1) ))\
.explode('VAR1').Product2.values输出数据df
VARIABLE1 Product1 Product2 Product3
0 3 111 101 102
1 2 98 101 104
2 4 97 101 98
3 5 105 102 95
4 1 85 102 110
5 6 101 102 98 您最终可以将dataframe写回字典:
mydict['VARIABLE1'] = df页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/63330539
复制相关文章
相似问题
腾讯云开发者
