
根据另一列中的值填充列
根据另一列中的值填充列
提问于 2020-07-31 14:29:08
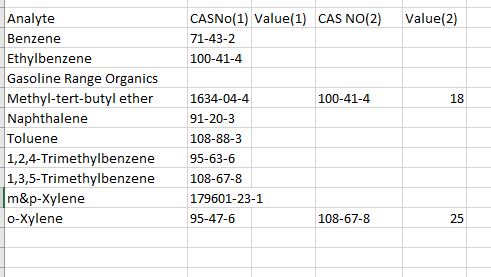
嗨,我正在和pandas一起操作一些实验室数据。我目前有一个包含5列的data frame。
- 前三列(分析、化学文摘社编号(1)和值)的顺序是正确的。
- 最后两列(化学文摘社编号2和值2)不是。
是否有一种方法可以根据匹配的CAS编号(也称为CAS NO(2)= CAS (NO1) )将CAS No(2)和Value(2)与前三列对齐。
我是python和pandas的新手。谢谢你的帮助
回答 3
Stack Overflow用户
发布于 2020-07-31 14:35:40
您可以重新排序列,方法是将df变量重新分配为在列表中索引的其本身的一个片段,该列表的条目是所讨论的列名。
colidx = ['Analyte', 'CAS NO(1)', 'CAS NO(2)']
df = df[colidx]Stack Overflow用户
发布于 2020-07-31 14:50:50
最好以文本格式提供输入数据,这样我们就可以复制粘贴它。我理解您的问题是这样的:您需要将最后两列排序在一起,以便CAS NO(2)与CAS NO(1)匹配。
因为CAS NO(2)=CAS(NO1),所以您不需要复制CAS NO(2)列,对吗?
拆分最后两列并从中生成一个Series,然后将该系列转换为dict,并使用该dict映射新值。
# Split 2 last columns and assign index.
df_tmp = df[['CAS NO(2)', 'Value(2)']]
df_tmp = df_tmp.set_index('CAS NO(2)')
# Keep only 3 first columns of original dataframe
df = df[['Analyte',' CASNo(1)', 'Value(1)']]
# Now copy the CasNO(1) to CAS NO(2)
df['CAS NO(2)'] = df['CasNO(1)']
# Now create Value(2) column on original dataframe
df['Value(2)'] = df['CASNo(1)'].map(df_tmp.to_dict()['Value(2)'])Stack Overflow用户
发布于 2020-07-31 15:16:26
尝试以下几点:
import pandas as pd
import numpy as np
#create an example of your table
list_CASNo1 = ['71-43-2', '100-41-4', np.nan, '1634-04-4']
list_Val1 = [np.nan]*len(list_CASNo1)
list_CASNo2 = [np.nan, np.nan, np.nan, '100-41-4']
list_Val2 = [np.nan, np.nan, np.nan, '18']
df = pd.DataFrame(zip(list_CASNo1, list_Val1, list_CASNo2, list_Val2), columns =['CASNo(1)','Value(1)','CAS NO(2)','Value(2)'], index = ['Benzene','Ethylbenzene','Gasonline Range Organics','Methyl-tert-butyl ether'])
#split the data to two dataframes
df1 = df[['CASNo(1)','Value(1)']]
df2 = df[['CAS NO(2)','Value(2)']]
#merge df2 to df1 based on the specified columns
#reset_index and set_index will take care
#that df_adjusted will have the same index names as df1
df_adjusted = df1.reset_index().merge(df2.dropna(),
how = 'left',
left_on = 'CASNo(1)',
right_on = 'CAS NO(2)').set_index('index')但是要小心列中的重复项,这样会导致合并失败。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/63193780
复制相关文章
相似问题
腾讯云开发者
