
在pd.read_html中使用Pandas = ' string‘参数无法识别表中的字符串,即使存在包含“string”的表
这个问题有两部分:
第一部分我试着用熊猫pd.read_html功能从SEC的网站上搜集一些数据。我只想要一个特定的表,它的文本“主体位置”在表中。我编写了一个脚本(见下文)来提取这些数据,但问题是它只在某些时候起作用。有时,它似乎完全忽略了包含此文本的表。
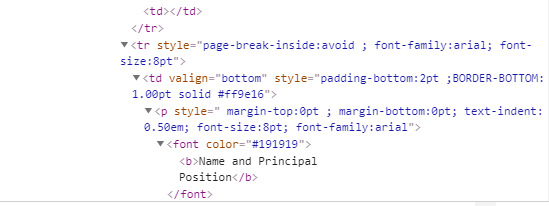
例如,在下面的脚本中,我试图为三家公司--微软( Microsoft )、亚马逊( Amazon )和特斯拉( Tesla )--提取包含“主体职位”字样的表格。虽然这三家公司都有一个包含“主体职位”字样的表格,但只有两个表格(MSFT和TSLA)被刮掉。由于找不到文本,第三个(AMZN)被跳过在try- not块中。我不知道我做错了什么会导致AMZN表被跳过。
任何帮助都将不胜感激!
第二部分----我还试图弄清楚如何使表的标题以包含“主体位置”的任何行开头。有时这个短语位于第二行,有时是第三行,等等。我不知道如何将pd.read_html中的headers参数设置为动态的,以便根据包含“主体位置”的任何一行进行更改。
理想情况下,我还希望去掉插入到表中的额外列(即所有“NaN”值的列)。
我知道我要一吨钱,但我想把它扔出去看看是否有人知道怎么做(我很困惑)。再次,非常感谢任何帮助!
我的代码(它跳过AMZN表,但确实刮了MSFT和TSLA表)
import pandas as pd
import html5lib
CIK_list = {'MSFT': 'https://www.sec.gov/Archives/edgar/data/789019/000119312519268531/d791036ddef14a.htm',
'AMZN': 'https://www.sec.gov/Archives/edgar/data/1018724/000119312520108422/d897711ddef14a.htm',
'TSLA': 'https://www.sec.gov/Archives/edgar/data/1318605/000156459020027321/tsla-def14a_20200707.htm',}
for ticker, link in CIK_list.items():
try:
df_list = pd.read_html(link, match=('Principal Position'))
df_list = pd.DataFrame(df_list[0])
df_list.to_csv(f'Z:/Python/{ticker}.csv')
except:
pass编辑的帖子:为了增加一些细节,我收到的错误如下:
ValueError: No tables found matching pattern 'Principal Position'然而,如果您查看AMZN文件的链接,您可以通过短信搜索“主体职位”,然后就会出现。可能是因为Pandas在执行read_html之前没有等待页面完全加载吗?
回答 1
Stack Overflow用户
发布于 2020-07-28 21:53:10
尝试:
df_list = pd.read_html(link, match=('Principal\s+Position'))因为从html代码来看,AMZN网页的主体和位置之间似乎不止有一个白空间。使用\s+ regex,这意味着一个或多个空间也将捕获此表。
https://stackoverflow.com/questions/63142115
复制相似问题
腾讯云开发者
