
由于准备状态检查失败,Google部署失败
自定义应用程序引擎环境无法启动,这似乎是由于健康检查失败所致。该应用程序有几个自定义依赖项(例如PostGIS、GDAL),因此在应用程序引擎映像上有几个层。它成功构建并在Docker容器中本地运行。
ERROR: (gcloud.app.deploy) Error Response: [4] Your deployment has failed to become healthy in the allotted time and therefore was rolled back. If you believe this was an error, try adjusting the 'app_start_timeout_sec' setting in the 'readiness_check' section.Dockerfile看起来如下(注意:在docker-compose.yml和app.yaml中没有定义作为入口点的CMD ):
FROM gcr.io/google-appengine/python
ENV PYTHONUNBUFFERED 1
ENV DEBIAN_FRONTEND noninteractive
RUN apt -y update && apt -y upgrade\
&& apt-get install -y software-properties-common \
&& add-apt-repository -y ppa:ubuntugis/ppa \
&& apt -y update \
&& apt-get -y install gdal-bin libgdal-dev python3-gdal \
&& apt-get autoremove -y \
&& apt-get autoclean -y \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/*
ADD requirements.txt /app/requirements.txt
RUN python3 -m pip install -r /app/requirements.txt
ADD . /app/
WORKDIR /app不幸的是,这会创建一个高达1.58GB的映像,但是最初的gcr.io python映像从1.05GB开始,所以我不认为图像的大小会是一个问题,也不应该是一个问题。
使用以下docker-compose.yml配置在本地运行这个配置,可以在短时间内漂亮地启动一个容器:
version: "3"
services:
web:
build: .
command: gunicorn gisapplication.wsgi --bind 0.0.0.0:8080因此,我希望下面的yaml.app能够做到这一点:
runtime: custom
env: flex
entrypoint: gunicorn -b :$PORT gisapplication.wsgi
beta_settings:
cloud_sql_instances: <sql-db-connection>
runtime_config:
python_version: 3不走运。因此,根据上面的错误,这似乎与准备状态检查有关。尝试增加应用程序启动的超时时间(15分钟!)以前似乎有过一些健康检查问题,从2019年9月起,退回到遗留健康检查还不是一个解决方案。
readiness_check:
path: "/readiness_check"
check_interval_sec: 10
timeout_sec: 10
failure_threshold: 3
success_threshold: 3
app_start_timeout_sec: 900
liveness_check:
path: "/liveness_check"
check_interval_sec: 60
timeout_sec: 4
failure_threshold: 3
success_threshold: 2
initial_delay_sec: 30分开的健康检查肯定在进行。gcloud beta app describe的输出是:
authDomain: gmail.com
codeBucket: staging.proj-id-000000.appspot.com
databaseType: CLOUD_DATASTORE_COMPATIBILITY
defaultBucket: proj-id-000000.appspot.com
defaultHostname: proj-id-000000.ts.r.appspot.com
featureSettings:
splitHealthChecks: true
useContainerOptimizedOs: true
gcrDomain: asia.gcr.io
id: proj-id-000000
locationId: australia-southeast1
name: apps/proj-id-000000
servingStatus: SERVING这不起作用,因此还试图增加实例可用的资源,并为一个CPU (6.1GB)分配最大内存量:
resources:
cpu: 1
memory_gb: 6.1
disk_size_gb: 10为了安全起见,我在应用程序中添加了健康检查端点(遗留健康检查和拆分健康检查)--这是一个Django应用程序,因此进入了该项目的urls.py
path(r'_ah/health/', lambda r: HttpResponse("OK", status=200)),
path(r'readiness_check/', lambda r: HttpResponse("OK", status=200)),
path(r'liveness_check/', lambda r: HttpResponse("OK", status=200)),因此,当我深入到日志中时,似乎有一个来自curl用户代理的对/liveness_check的成功请求,但随后从GoogleHC代理对/readiness_check的请求返回了503 (服务不可用)。
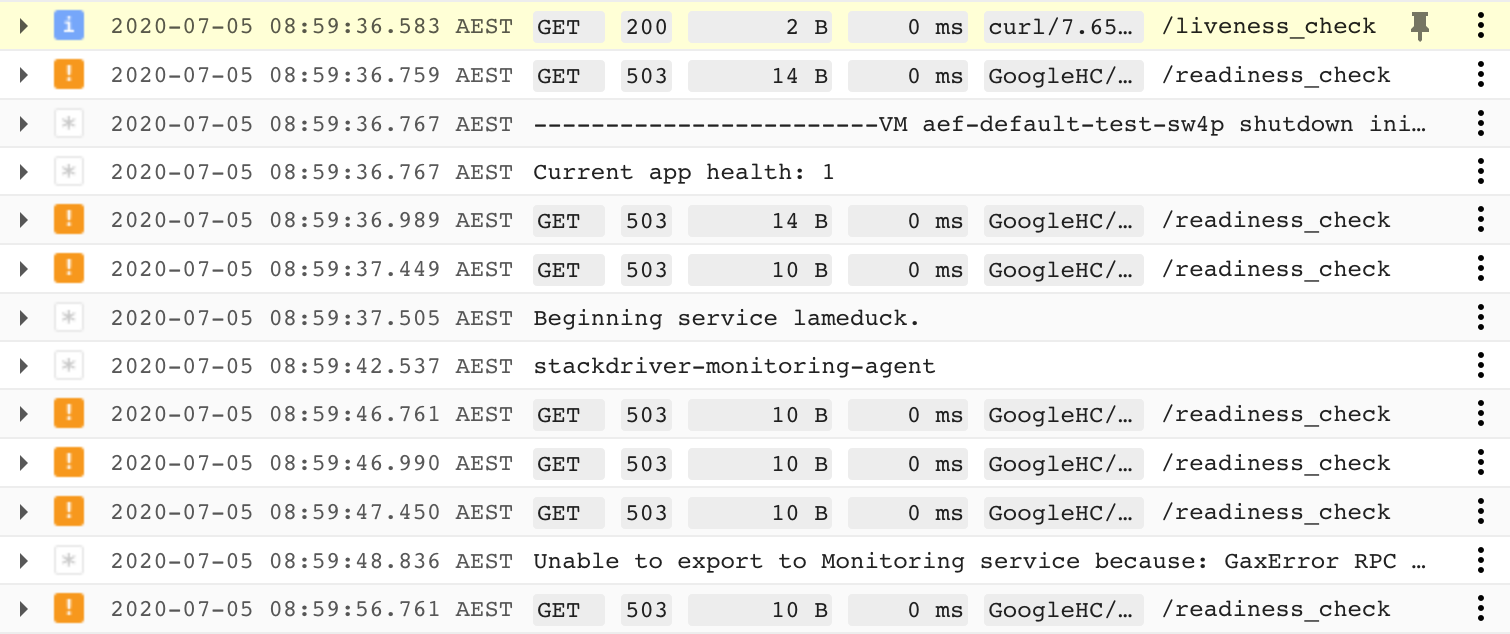
之后不久(在8次请求失败后-为什么是8次?)似乎发送了一个关闭触发器:
2020-07-05 09:00:02.603 AEST Triggering app shutdown handlers.对这里发生了什么有什么想法吗?我想我已经用尽了解决这个问题的各种选择,我想知道在Compute/EC2中是否没有更好的时间投入到启动和运行上。
增编
Stack Overflow用户
发布于 2020-07-05 05:53:14
您正在将就绪检查发送到path: "/readiness_check",但您的url处理程序是path(r'readiness_check/'...)。
注意处理程序中的尾斜杠。删除它(或者在readiness_check:的路径中添加一个尾随斜杠),看看是否修复了它。我认为这会给您一个404,但是您正在得到一个503,它告诉我您可能有一个更严重的错误。单击控制台中503左侧的箭头之一,查看错误消息是什么。您可能需要在控制台中搜索traceback才能看到它。
https://stackoverflow.com/questions/62735687
复制相似问题
腾讯云开发者
