
如何自动启动人工智能平台作业?
如何自动启动人工智能平台作业?
提问于 2020-06-27 15:42:30
我创建了一个培训作业,从大查询中获取数据,执行培训和部署模型。我想在这两种情况下自动开始训练:
- 向dataset
- 添加了1000多个新行,并有一个计划(Ex,每周一次)
我检查了,但它似乎不适合我的情况。
回答 1
Stack Overflow用户
发布于 2020-11-06 05:51:35
对于任何想要按时提交培训工作的解决方案的人,我尝试了几种方法后,在这里发布我的解决方案。
- 使用气流
- 启动作业运行云编写器使用开始脚本
- 使用cron与云调度程序、Pub/Sub和云函数
最简单、最具成本效益的方法是使用云调度器和具有云功能的人工智能平台客户端库。
步骤1-创建发布/子主题(例如start-training)
步骤2-使用针对start-training主题的云调度程序创建cron
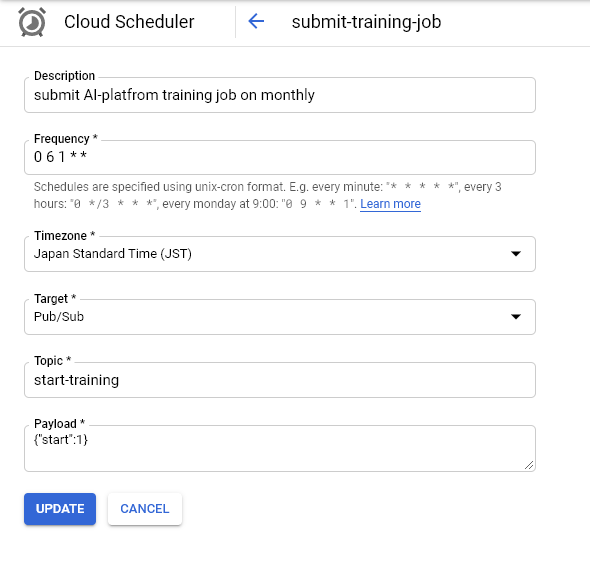
步骤3-使用触发器类型作为cloud pub/sub,主题作为start-training创建云函数,入口点是submit_job,function.This函数,通过python库向人工智能平台提交培训作业。
现在我们有了这个漂亮的DAG
计划程序-> Pub/子->云功能-> AI-platform
云函数代码如下所示
main.py
import datetime
from googleapiclient import discovery
from oauth2client.client import GoogleCredentials
id = '<PROJECT ID>'
bucket_name = "<BUCKET NAME>"
project_id = 'projects/{}'.format(id)
job_name = "training_" + datetime.datetime.now().strftime("%y%m%d_%H%M%S")
def submit_job(event, context):
training_inputs = {
'scaleTier': 'BASIC',
'packageUris': [f"gs://{bucket_name}/package/trainer-0.1.tar.gz"],
'pythonModule': 'trainer.task',
'region': 'asia-northeast1',
'jobDir': f"gs://{bucket_name}",
'runtimeVersion': '2.2',
'pythonVersion': '3.7',
}
job_spec = {"jobId":job_name, "trainingInput": training_inputs}
cloudml = discovery.build("ml" , "v1" ,cache_discovery=False)
request = cloudml.projects().jobs().create(body=job_spec,parent=project_id)
response = request.execute()requirement.txt
google-api-python-client
oauth2client重要
Project_name,
- 确保使用Project_id而不是Project_id,否则会导致权限错误
- 如果在构建函数中使用
ImportError:file_cache is unavailable when using oauthclient ....错误使用cache_discovery=False,则保留函数使用缓存是因为性能原因。
task
- 指向将GCS位置更正到源包的位置,在本例中,我的包名是
trainer构建的,位于桶中的package文件夹中,主模块是trainer。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/62612079
复制相关文章
相似问题
腾讯云开发者
