
从找到的字符串中读取最后一个字符或位置
从找到的字符串中读取最后一个字符或位置
提问于 2020-06-15 19:35:22
我看过Regex Last occurrence?,但无法让正则表达式对我的示例字符串("https://www.fakesite.com test one")起作用。我需要返回网站名称的最后一个字符(或职位)。我有两个捕获网站和获得最后一个字符的表达式,但不能得到表达式,以获得正确的后面看。
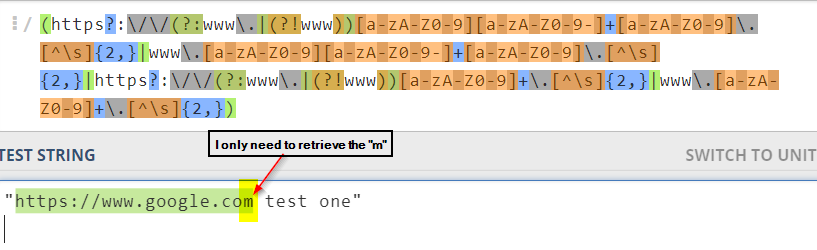
(https?:\/\/(?:www\.|(?!www))[a-zA-Z0-9][a-zA-Z0-9-]+[a-zA-Z0-9]\.[^\s]
{2,}|www\.[a-zA-Z0-9][a-zA-Z0-9-]+[a-zA-Z0-9]\.[^\s]{2,}|https?:\/\/(?:www\.|
(?!www))[a-zA-Z0-9]+\.[^\s]{2,}|www\.[a-zA-Z0-9]+\.[^\s]{2,}) <- Regular Expression for website
(?=.?$). <- Regular Expression for retrieving last character我一直在用https://regex101.com/来尝试寻找,但没有运气。
如何检索最后一个字符或位置?
--编辑--
如何检索任何字符串的最后一个字符?(我只需要系统工程师中的字母'r‘)。“系统工程师”是动态的。
为系统工程师的职位设于
(?<=position of )(.*)(?= located) <- regex to capture System Engineer between words 'position of' and 'located'回答 1
Stack Overflow用户
回答已采纳
发布于 2020-06-16 01:40:47
你可以试试下面的正则表达式。下面的regex将检查有效的url地址以及您的url的最后一个字符。
https?:\/\/(?:www\.)?[-a-zA-Z0-9@:%._\+~#=]{1,256}\.[a-zA-Z0-9()]{1,6}(\w)\b(?:[-a-zA-Z0-9()@:%_\+.~#?&\/\/=]*)对上述正则表达式的解释:
https?:\/\/(?:www\.)?[-a-zA-Z0-9@:%._\+~#=]{1,256} -匹配正则表达式的http/https://部分以及第一个.之前的www和域名。
[a-zA-Z0-9()]{1,6} -这个部分与url部分的最后一个部分相匹配。
(\w) -表示捕获url的最后一个字符的捕获组。如果不想包含([a-zA-Z0-9]),可以手动使用_。
\b(?:[-a-zA-Z0-9()@:%_\+.~#?&\/\/=]*) -匹配url的其余部分,如.uk或.in等,0次或多次。
您可以在中找到上述正则表达式的演示。
引用:匹配有效url的正则表达式摘自 应答.。
如果希望在regex中进行修改,只需在regex后面添加[a-zA-Z]即可。您可以找到演示
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/62395646
复制相关文章
相似问题
腾讯云开发者
