
在多个组中查找唯一的ID数
我有一个数据集,里面有医生和他们工作的各种实践。我的数据集中的每个医生至少在1次实践中工作,但多达17次不同的实践。我想知道每一个工作的医生的独特数目。当前的数据集在SAS中,但我熟悉Python、Pandas和SQL。我很好地将数据转换成所需的任何格式,所以答案不需要在SAS代码中。
下面的示例数据集。这个样本显示A博士在实践中,P1,P3,和P5。E博士正在实践P1、P2和P5等。
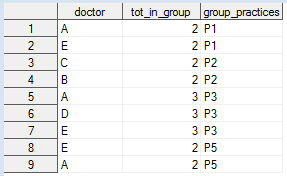
从这张图表中,我想要一个新的列,列上每个人工作的唯一医生的总数。在这种情况下,A医生与其他2名医生合作(E &D)然而,如果我简单地按医生分组并进行总结,我发现A博士与6位医生一起工作。然而,这是错误的,因为它会数A医生3次(每列一次)和数E医生两次(他在A、P1和P5医生的两组练习中)
我有80万名医生,其中有40万名集体练习,使手工方法不可行。有谁对如何开始这件事有什么建议吗?
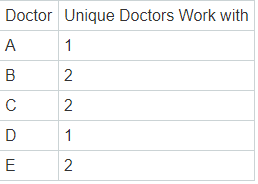
最后的输出如下:
示例数据集代码(用于SAS)
input doctor $ tot_in_group group_practices $;
datalines;
A 2 P1
E 2 P1
C 3 P2
B 3 P2
E 3 P2
A 2 P3
D 2 P3
E 2 P5
A 2 P5
;
run;回答 4
Stack Overflow用户
发布于 2020-06-05 19:30:35
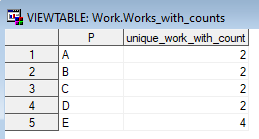
不包括自配对的组内的自我连接将生成每个组的所有配对的表。使用这一概念作为基础,为每一位医生计算不同的“伴侣”,而不是所有的小组。
要获得真正的唯一性,请确保您使用的是与每个个体不同的doctorId。试图阻止基于名字的“自我配对”是自找麻烦。(想想杜威医生、杜威医生和杜威医生--是的麻烦)
data have;
input doctor $ group $;
datalines;
A P1
E P1
C P2
B P2
E P2
A P3
D P3
E P3
E P5
A P5
;
run;
proc sql;
* demonstrate the combinatoric effect of who (P) paired with whom (Q) within group;
* do not submit against the big data;
create table works_with_each as
select
P.doctor as P
, Q.doctor as Q
, P.group
from have as P
join have as Q
on P.group = Q.group
& P.doctor ^= Q.doctor
order by
P.doctor, Q.doctor, P.group
;
* count the distinct pairing, regardless of group;
create table works_with_counts as
select
P.doctor as P
, count(distinct Q.doctor) as unique_work_with_count
from have as P
join have as Q
on P.group = Q.group
& P.doctor ^= Q.doctor
group by
P.doctor
order by
P.doctor
; 每一个
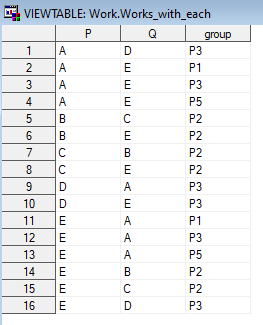
唯一的对(工作)计数
Stack Overflow用户
发布于 2020-06-05 17:43:13
您可能需要在您的语言(特别是COUNT(DISTINCT var))中使用更多的查询来完成这个任务。
SELECT docA , COUNT(DISTINCT docB) FROM
(SELECT A.doctor as docA, B.doctor as docB FROM mytable A JOIN mytable B
ON A.group_practices = B.group_practices WHERE A.doctor > B.doctor)
GROUP BY docA然后,您可以将此表加入到您前面展示的on doctor = docA表中。
docA>docB防止有:
A in relation with A,- 或者有像
A in relation in B和B in relation with A这样的副本
Stack Overflow用户
发布于 2020-06-05 18:01:40
你可以自己加入和聚合:
select t.doctor, count(distinct t1.doctor) no_coworkers
from mytable t
inner join mytable t1 on t1.doctor <> t.doctor and t1.group_practices = t.group_practices
group by t.doctorhttps://stackoverflow.com/questions/62221168
复制相似问题
腾讯云开发者
