
在回归模型评价中,考虑了为什么SKLEARN中的负(MSE或MAS)评分参数类似于- neg_mean_absolute_error。
我是机器学习的新手,在学习过程中遇到了“评分参数”。对于回归模型的评价,我们考虑了均方误差、平均绝对误差等的负面因素。
当我想知道原因时,我查阅了SKLearn文档,其中说:“所有scorer对象都遵循这样的约定:返回值越高,返回值越低。因此,度量模型与数据之间的距离的度量,如metrics.mean_squared_error,可以作为返回度量的负值的neg_mean_squared_error。”
这个解释没有完全回答我的原因,我很困惑。那么,为什么负面效应会更多,因为从逻辑上讲,无论是-ve还是+ve,如果预测的差异更大,那么我们的模型也会同样糟糕。那么,为什么评分参数集中在负差异上呢?
回答 2
Stack Overflow用户
发布于 2020-06-01 12:15:12
我认为在你理解neg_mean_absolute_error (NMAE)的方式上有一个小小的误解。计算neg_mean_absolute_error的方式如下:
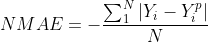
其中N是数据点的总数,Y_i是真值,Y_i^p是预测值。
不过,如果模型预测的值高于或低于真实值,我们同样会对其进行惩罚,但我们只是将最终结果与-1相乘,以遵循sklearn所设定的惯例。因此,如果一个模型给你一个MAE,比如说0.55,另一个模型给你一个MAE,比如0.78,它们的NMAE值将被转换为-0.55和-0.78,通过遵循越高越好的惯例,我们选择前者的模型,它的结果具有较高的NMAE of -0.55。
您可以为MSE提出类似的论点。
Stack Overflow用户
发布于 2020-06-01 04:57:01
它很简单:最小化MSE等同于最大化负MSE。
一个目标函数,得分手可以最大限度地是通过“约定”,正如Sklearn文档所建议的。
https://stackoverflow.com/questions/62125674
复制相似问题
腾讯云开发者
