
Python刮取数组,但首先要进入默认页面
Python刮取数组,但首先要进入默认页面
提问于 2020-05-22 01:10:07
我想在这个治安官的销售页面上搜索个人名单的细节。到目前为止,我已经在一个数组中收集了要抓取的urls列表。然而,我遇到的问题是,当网址是自己输入的时候,他们默认使用这个页面,这个网站有治安官销售的所有县:https://salesweb.civilview.com/。我想,我需要张贴网站的曲奇,因为我通过数组排序,但任何帮助将不胜感激。我在jupyter和python 3工作。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
import requests
import requests.cookies
import time
from urllib.request import urlopen
from bs4 import BeautifulSoup
# URL that I want to get to collect house details from.
url = "https://salesweb.civilview.com/Sales/SalesSearch?countyId=23"
html = urlopen(url)
soup = BeautifulSoup(html,'html.parser')
type(soup)
# collect the links for all of the houses
records = []
for item in soup.find_all('a', href = True):
if item.text:
records.append(item['href'])
print(records)
# add beginning part of house url's because the href does not include the entire url
string = 'https://salesweb.civilview.com'
my_new_list = [string + x for x in records]
print (my_new_list)
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36',
'Referer': "https://salesweb.civilview.com/"}
# Just want to test if i can collect information from individual house, this is where i get the error
for house in my_new_list:
session.post(url, cookies = cj, headers = headers)
houses = requests.get(house)
soup_pages = BeautifulSoup(houses.content, 'html.parser')
#print body only
table = soup_pages.find_all('td')
print(table)回答 1
Stack Overflow用户
回答已采纳
发布于 2020-05-22 09:27:51
此脚本将遍历每个县并将所有信息存储到字典all_data中,然后从它创建数据格式并将其保存为csv:
import requests
from bs4 import BeautifulSoup
import pandas as pd
url = 'https://salesweb.civilview.com/'
soup = BeautifulSoup(requests.get(url).content, 'html.parser')
urls = [(a.text, 'https://salesweb.civilview.com' + a['href']) for a in soup.select('a')]
all_data = {'County':[], 'Sheriff No': [], 'Status': [], 'Sales Date': [], 'Attorney': [], 'Parcel No': [], 'Plaintiff': [], 'Defendant': [], 'Address': []}
for county, url in urls:
print('Processing {} URL={}...'.format(county, url))
soup = BeautifulSoup(requests.get(url).content, 'html.parser')
for tr in soup.select('tr:has(td)'):
# print( tr.select('td') )
tds = tr.select('td')
if len(tds) == 6:
_, sheriff_no, sales_date, plaintiff, defendant, address = tds
status = '-'
attorney = '-'
parcel_no = '-'
elif len(tds) == 7:
_, sheriff_no, status, sales_date, plaintiff, defendant, address = tds
status = status.get_text(strip=True)
attorney = '-'
parcel_no = '-'
elif len(tds) == 9:
_, status, sales_date, sheriff_no, attorney, plaintiff, parcel_no, defendant, address = tds
status = status.get_text(strip=True)
attorney = attorney.get_text(strip=True)
parcel_no = '-'
all_data['County'].append(county)
all_data['Sheriff No'].append(sheriff_no.get_text(strip=True))
all_data['Status'].append(status)
all_data['Sales Date'].append(sales_date.get_text(strip=True))
all_data['Plaintiff'].append(plaintiff.get_text(strip=True))
all_data['Attorney'].append(attorney)
all_data['Parcel No'].append(parcel_no)
all_data['Defendant'].append(defendant.get_text(strip=True))
all_data['Address'].append(address.get_text(strip=True))
# all information is stored now in `all_data`, but let's create a dataframe from it:
df = pd.DataFrame(all_data)
print(df)指纹:
Processing Allen County, OH URL=https://salesweb.civilview.com/Sales/SalesSearch?countyId=34...
Processing Atlantic County, NJ URL=https://salesweb.civilview.com/Sales/SalesSearch?countyId=25...
...
County Sheriff No Status ... Plaintiff Defendant Address
0 Atlantic County, NJ F-20000248 - ... Ocean City Home Bank... Richard W. Lemmerman... 5348 White Horse Pike Mailing Address: Egg Har...
1 Atlantic County, NJ F-19001833 - ... Selene Finance LP... Darrin M. Lord;Susan... 9 Saint Andrews Drive Northfield NJ 08225
2 Atlantic County, NJ F-19001941 - ... The Bank of New York... Raymond Mooney; Donn... 574 Revere Way Galloway Township NJ 08205
3 Bergen County, NJ F-18001316 - ... MTGLQ INVESTORS, LP JENNIFER A. SKOVRAN, ET AL. 21-06 DALTON PLACE FAIR LAWN NJ 07410
4 Bergen County, NJ F-18001967 - ... U.S. BANK NATIONAL ASSOCIATION, AS TRUSTEE FOR... HENRY CASANOVA, ET ALS. 488 VICTOR STREET SADDLE BROOK NJ 07663
... ... ... ... ... ... ... ...
2288 Union County, NJ CH-19000471 - ... US BANK NATIONAL ASSOCIATION, AS TRUSTEE FOR C... ROBERT E. HARRIS, ELLEN HARRIS, WELLS FARGO BA... 98 BELMONT AVENUE CRANFORD NJ 07016
2289 Union County, NJ CH-19001682 - ... WELLS FARGO BANK, N.A. SONNY CORREA A/K/A SONNY P. CORREA; RUBENIA CO... 813-15 WEST FOURTH STREET PLAINFIELD NJ 07063
2290 Union County, NJ CH-19002054 - ... WELLS FARGO BANK, N.A. MANUEL BARREIRA, LAUREN E. BARREIRA, UNITED ST... 524 WILLOW AVENUE ROSELLE PARK NJ 07204
2291 Union County, NJ CH-19002308 - ... U.S. BANK NATIONAL ASSOCIATION, AS TRUSTEE FOR... LAUREN LEASTON AKA LAUREN S. LEASTON, UNITED S... 418-420 GREEN COURT PLAINFIELD NJ 07060
2292 Union County, NJ CH-19002582 - ... U.S. BANK NA, SUCCESSOR TRUSTEE TO BANK OF AME... EMILIE JOSEPH; ACB RECEIVABLES; AND NEWARK BET... 1239 VICTOR AVENUE UNION NJ
[2293 rows x 9 columns]data.csv在LibreOffice开幕时:
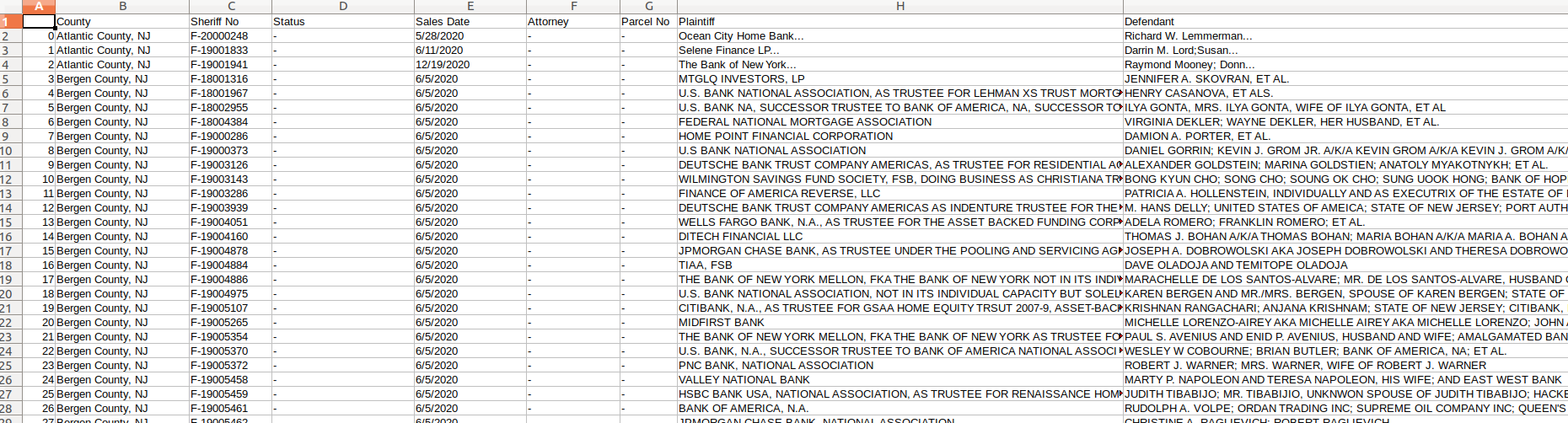
编辑(以获得蒙哥马利县的详细数据,PA):
import requests
import pandas as pd
from bs4 import BeautifulSoup
# url of Montgomery County, PA:
url = 'https://salesweb.civilview.com/Sales/SalesSearch?countyId=23'
with requests.session() as s:
soup = BeautifulSoup(s.get(url).content, 'html.parser')
data = []
for a in soup.select('a:contains("Details")'):
url = 'https://salesweb.civilview.com' + a['href']
print('Processing URL={}...'.format(url))
soup = BeautifulSoup(s.get(url).content, 'html.parser')
t = []
for tr in soup.table.select('tr'):
title, value, _ = tr.select('td')
t.append((title.get_text(strip=True).replace('#&colon', '').replace('&colon', ''), value.get_text(strip=True, separator='\n')))
data.append(dict(t))
df = pd.DataFrame(data)
print(df)
df.to_csv('data.csv')指纹:
...
Processing URL=https://salesweb.civilview.com/Sales/SaleDetails?PropertyId=877879948...
Processing URL=https://salesweb.civilview.com/Sales/SaleDetails?PropertyId=877879634...
Processing URL=https://salesweb.civilview.com/Sales/SaleDetails?PropertyId=877879962...
Processing URL=https://salesweb.civilview.com/Sales/SaleDetails?PropertyId=877879654...
Sheriff Court Case Sales Date Plaintiff ... Attorney Phone Parcel Law Reporter Township
0 18002083 18-03910 5/27/2020 HSBC Bank USA, N.A. ... 215-790-1010 49-00-00142-00-7 Plymouth Township
1 17011341 17-24059 5/27/2020 CitiMortgage, Inc. ... 215 942-2090 ext 1337 46-00-00005-26-4 Montgomery Township
2 11008592 11-16634 5/27/2020 Wells Fargo Bank ... 215-790-1010 37-00-00742-13-9 Limerick Township
3 18005541 18-05020 5/27/2020 Souderton Area School District ... 866-211-9466 34-00-00590-42-9 Franconia Township
4 19002379 19-03925 5/27/2020 PNC Bank, National Association ... 614-220-5611 46-00-00666-18-8 Montgomery Township
.. ... ... ... ... ... ... ... ... ...
351 19000239 19-00174 9/30/2020 J.P. Morgan Mortgage Acquisition Corp. ... 856-384-1515 31-00-21991-00-1 Cheltenham Township
352 19010961 19-24540 9/30/2020 Bayview Loan Servicing, LLC ... 614-220-5611 01-00-03754-00-7 Ambler Borough
353 19006687 19-16329 9/30/2020 The Bank of New York Mellon, et al ... 516-699-8902 04-00-00809-10-5 Collegeville Borough
354 19011323 19-25220 9/30/2020 Wells Fargo Bank, N.A. ... 614-220-5611 52-00-18466-00-4 Springfield Township
355 19007225 19-18256 9/30/2020 NewRez LLC ... 516-699-8902 13-00-00384-00-8 Norristown Borough
[356 rows x 13 columns]data.csv看起来像:
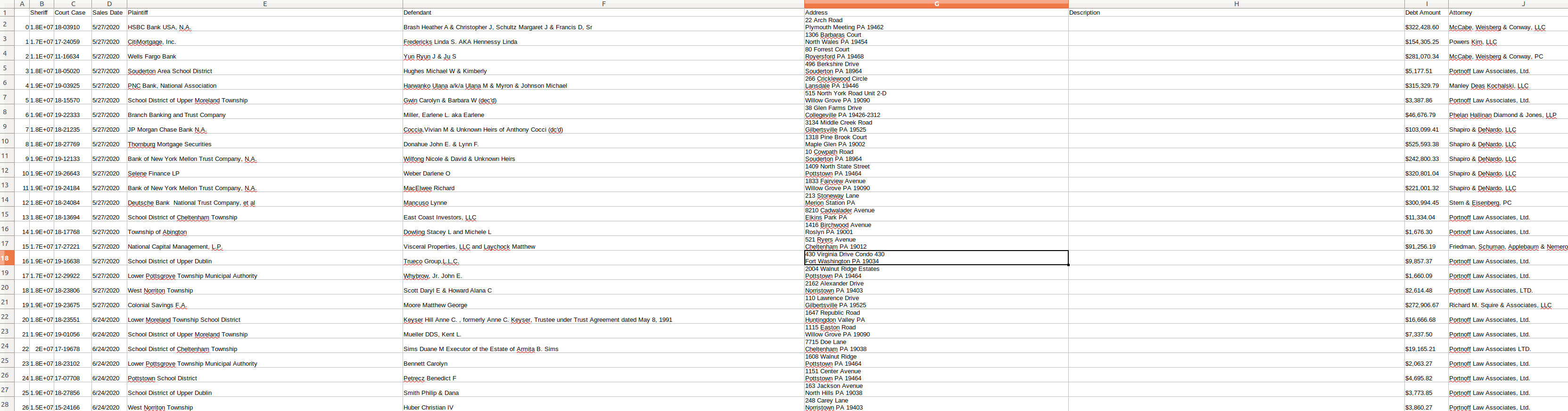
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/61946281
复制相关文章
相似问题
腾讯云开发者
