
Mp.set_start_method(“产卵”)触发了一个错误,说明已经设置了上下文
这是我的完整代码
我已经成功地用一个小片段再现了我的主要代码的行为。
在Google 中,假设我将hardware accelerator设置为GPU。
下面是一个小片段:
import multiprocessing as mp
def foo(q):
q.put('hello')
if __name__ == '__main__':
mp.set_start_method('spawn')
q = mp.Queue()
p = mp.Process(target=foo, args=(q,))
p.start()
print(q.get())
p.join()使用mp.set_start_method('spawn'),我得到了错误RuntimeError: context has already been set,如果我使用mp.set_start_method('spawn', force=True),它会陷入无限循环(如果我可以这么说的话)。
有什么办法可以防止这个错误发生在Colab Env吗?
P.S.注意这行代码在我的代码中是必要的。否则,我得到了错误RuntimeError: Cannot re-initialize CUDA in forked subprocess. To use CUDA with multiprocessing, you must use the 'spawn' start method
过载溶液
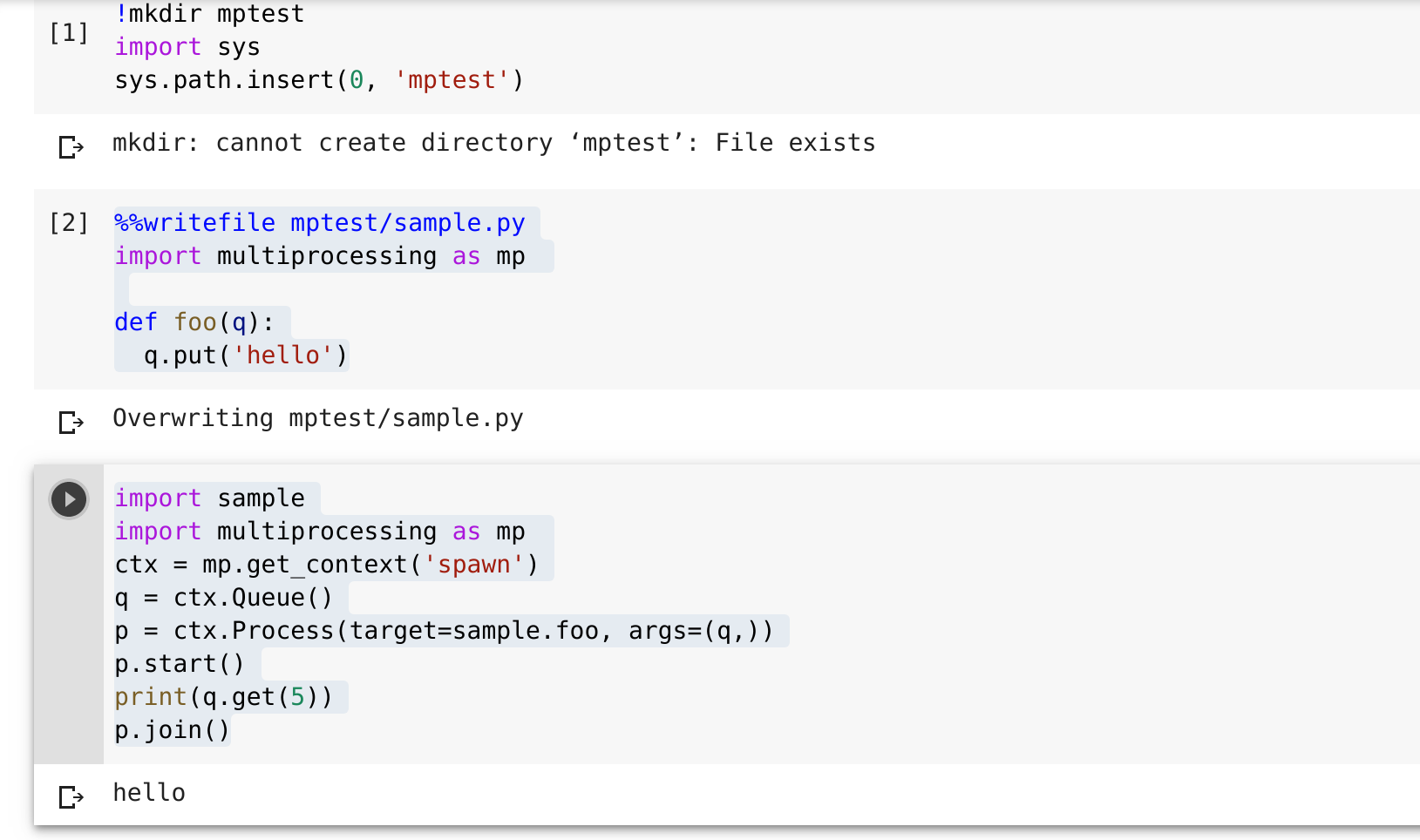
这里的问题是生成的子进程无法找到__main__.foo。
一个(不太完美)选项是将代码放在一个单独的文件中,例如创建一个新目录并将其添加到路径中。
我不想使用这个解决方案,因为它对我的主要代码来说太过分了。也许它会引导你找到一个更优雅的解决方案。
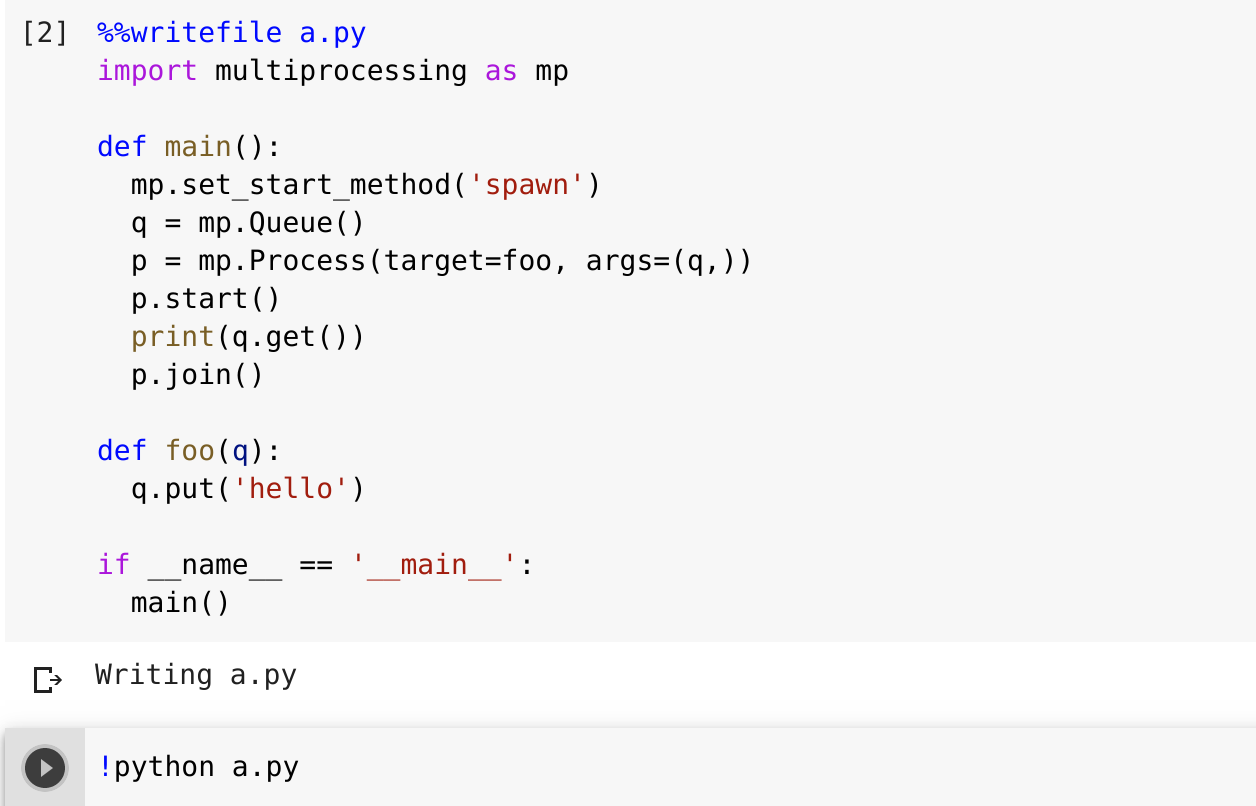
更新
这似乎是一个更合理的解决方案,但仍在寻找一个更优雅的答案。
回答 1
Stack Overflow用户
发布于 2022-03-25 11:37:13
在函数调用(main除外)之前,您应该将start方法设置为派生方法。
示例用法:
import multiprocessing as mp
try:
mp.set_start_method('spawn', force=True)
print("spawned")
except RuntimeError:
pass在PyTorch中,我通常使用这个块进行多进程推理。
https://stackoverflow.com/questions/61939952
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号