
Selenium:如何单击“显示”按钮,刮除“参考资料”,然后再单击“显示”按钮?
Selenium:如何单击“显示”按钮,刮除“参考资料”,然后再单击“显示”按钮?
提问于 2020-04-15 16:25:08
链接到我正在尝试刮的页面:
https://www.nytimes.com/reviews/dining
因为这个页面有一个“显示更多”按钮,我需要Selenium迭代地自动单击“显示更多”按钮,然后以某种方式使用漂亮汤来获取页面上每个单独餐馆评论的链接。在下面的照片中,我想要获取的链接在">https://...onigiri.html">中。
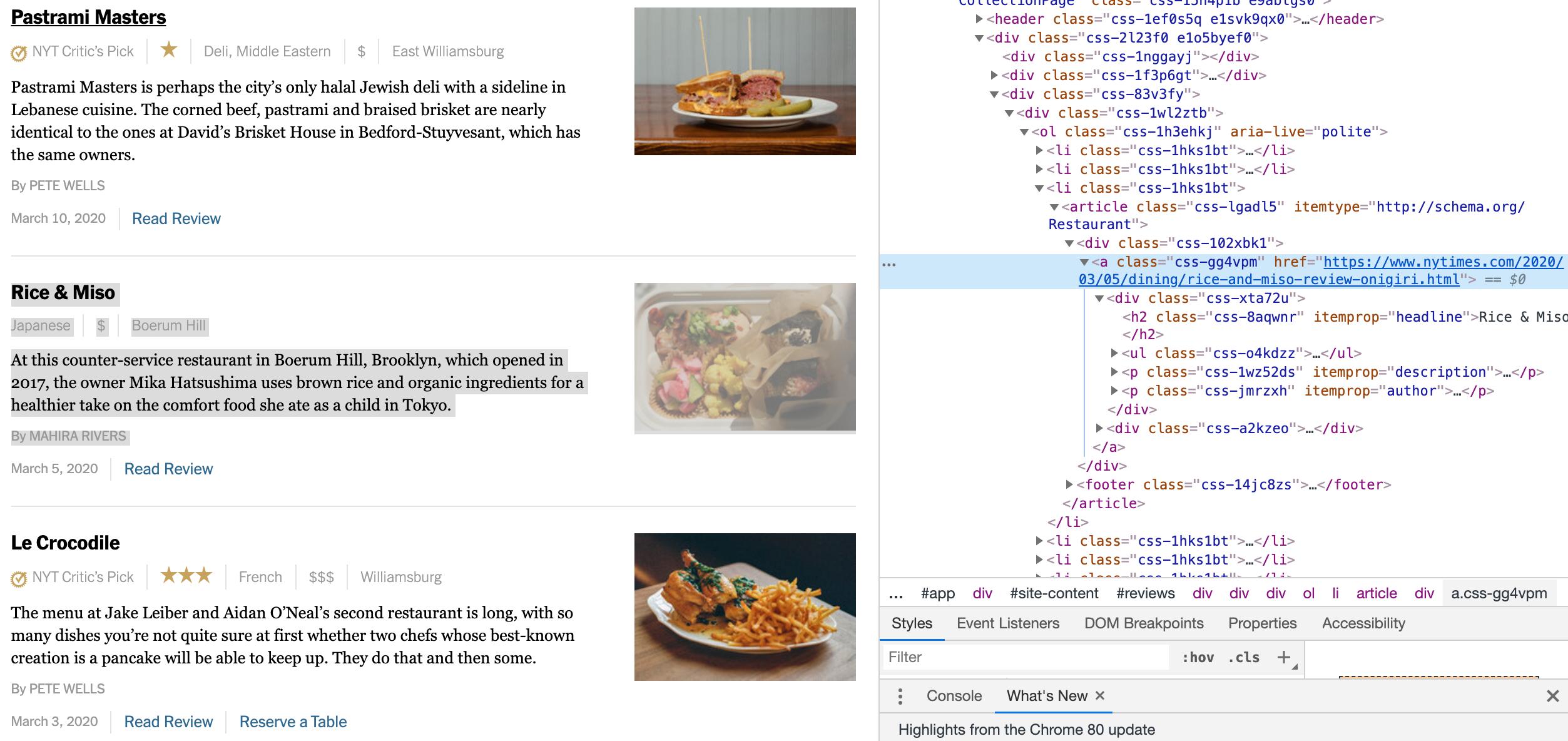
目前为止的代码:
url = "https://www.nytimes.com/reviews/dining"
driver = webdriver.Chrome('chromedriver',chrome_options=chrome_options)
driver.get(url)
for i in range(1):
button = driver.find_element_by_tag_name("button")
button.click()如何使用WebDriverWait和BeautifulSoup BeautifulSoup(driver.page_source,'html.parser')来完成此任务?
回答 2
Stack Overflow用户
回答已采纳
发布于 2020-04-16 10:30:08
这是一个延迟加载application.To,单击Show More按钮,您需要使用infinite循环,然后使用scroll down查找页面,然后等待一段时间来加载页面,然后将值存储在list.Verify列表中,如果匹配,则从无限循环中分离出来。
码
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium import webdriver
import time
driver=webdriver.Chrome()
driver.get("https://www.nytimes.com/reviews/dining")
#To accept the coockie click on that
WebDriverWait(driver,20).until(EC.element_to_be_clickable((By.XPATH,"//button[text()='Accept']"))).click()
listhref=[]
while(True):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
elements=WebDriverWait(driver,20).until(EC.visibility_of_all_elements_located((By.CSS_SELECTOR,"a.css-gg4vpm")))
lenlistbefore=len(listhref)
for ele in elements:
if ele.get_attribute("href") in listhref:
continue
else:
listhref.append(ele.get_attribute("href"))
lenlistafter = len(listhref)
if lenlistbefore==lenlistafter:
break
button=WebDriverWait(driver,10).until(EC.visibility_of_element_located((By.XPATH,"//button[text()='Show More']")))
driver.execute_script("arguments[0].click();", button)
time.sleep(2)
print(len(listhref))
print(listhref)注意事项:-我得到了列表计数499
Stack Overflow用户
发布于 2020-04-15 17:48:52
转到https://www.nytimes.com/reviews/dining按F12,然后按Ctrl+Shift+C以获取元素显示更多的,然后如我在图中所示,获取元素的xpath:

为了找到xpath,请查看:
https://www.techbeamers.com/locate-elements-selenium-python/#locate-element-by-xpath
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
def executeTest():
global driver
driver.get('https://www.nytimes.com/reviews/dining')
time.sleep(7)
element = driver.find_element_by_xpath('Your_Xpath')
element.click()
time.sleep(3)
def startWebDriver():
global driver
options = Options()
options.add_argument("--disable-infobars")
driver = webdriver.Chrome(chrome_options=options)
if __name__ == "__main__":
startWebDriver()
executeTest()
driver.quit()页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/61233709
复制相关文章
相似问题
腾讯云开发者
